1.3 Stages of Building and Using LLMs
- The general process of creating an LLM includes pretraining and fine-tuning.
- The “pre” in “pretraining” refers to the initial phase where a model like an LLM is trained on a large, diverse dataset to develop a broad understanding of language. This pretrained model then serves as a foundational resource that can be further refined through fine-tuning, a process where the model is specifically trained on a narrower dataset that is more specific to particular tasks or domains.
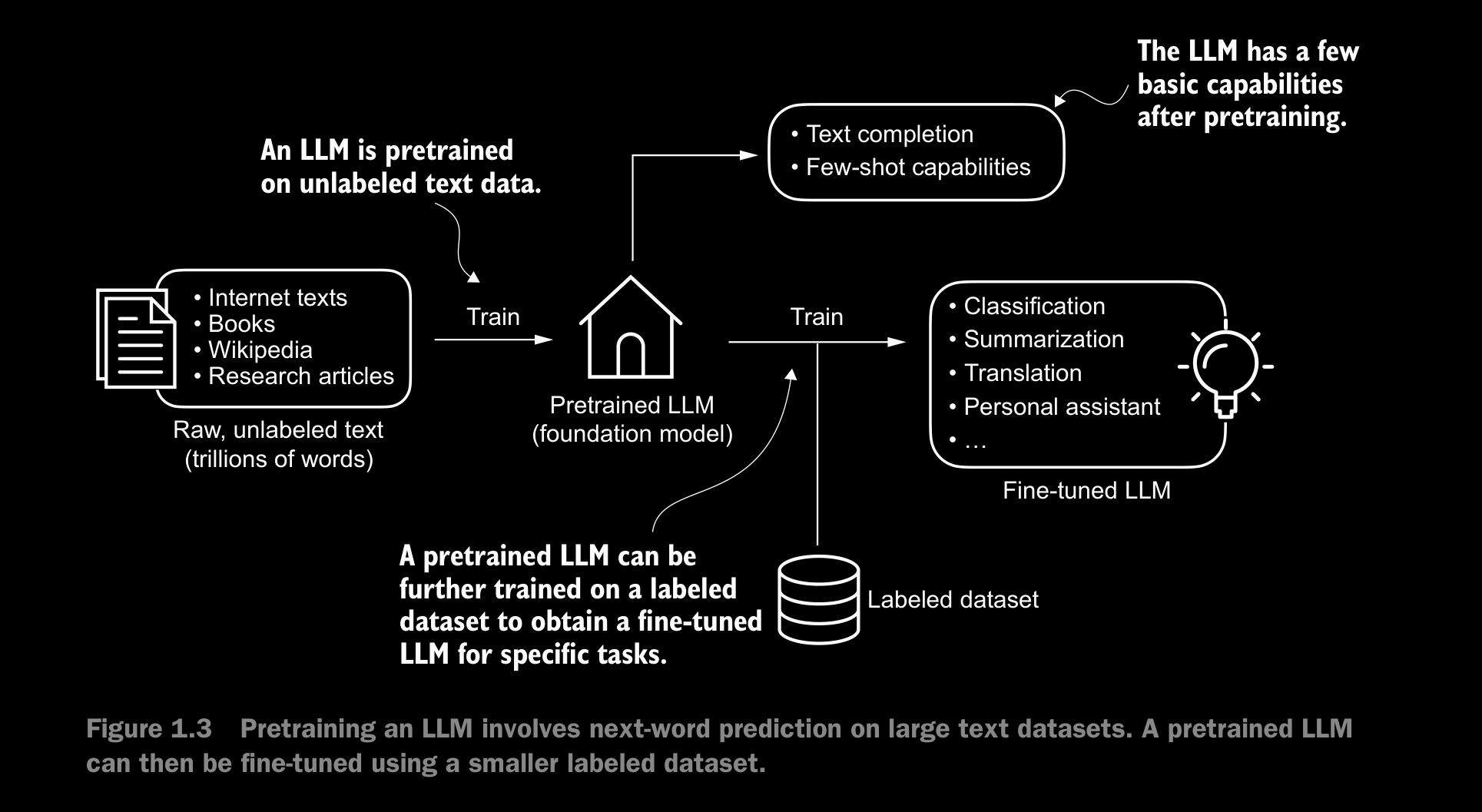
- In the pretraining phase, LLMs use self-supervised learning, where the model generates its own labels from the input data.
- After obtaining a pretrained LLM from training on large text datasets, where the LLM is trained to predict the next word in the text, we can further train the LLM on labeled data, also known as fine-tuning.
- The two most popular categories of fine-tuning LLMs are instruction fine-tuning and classification fine-tuning.
1.4 Introducing the transformer architecture
-
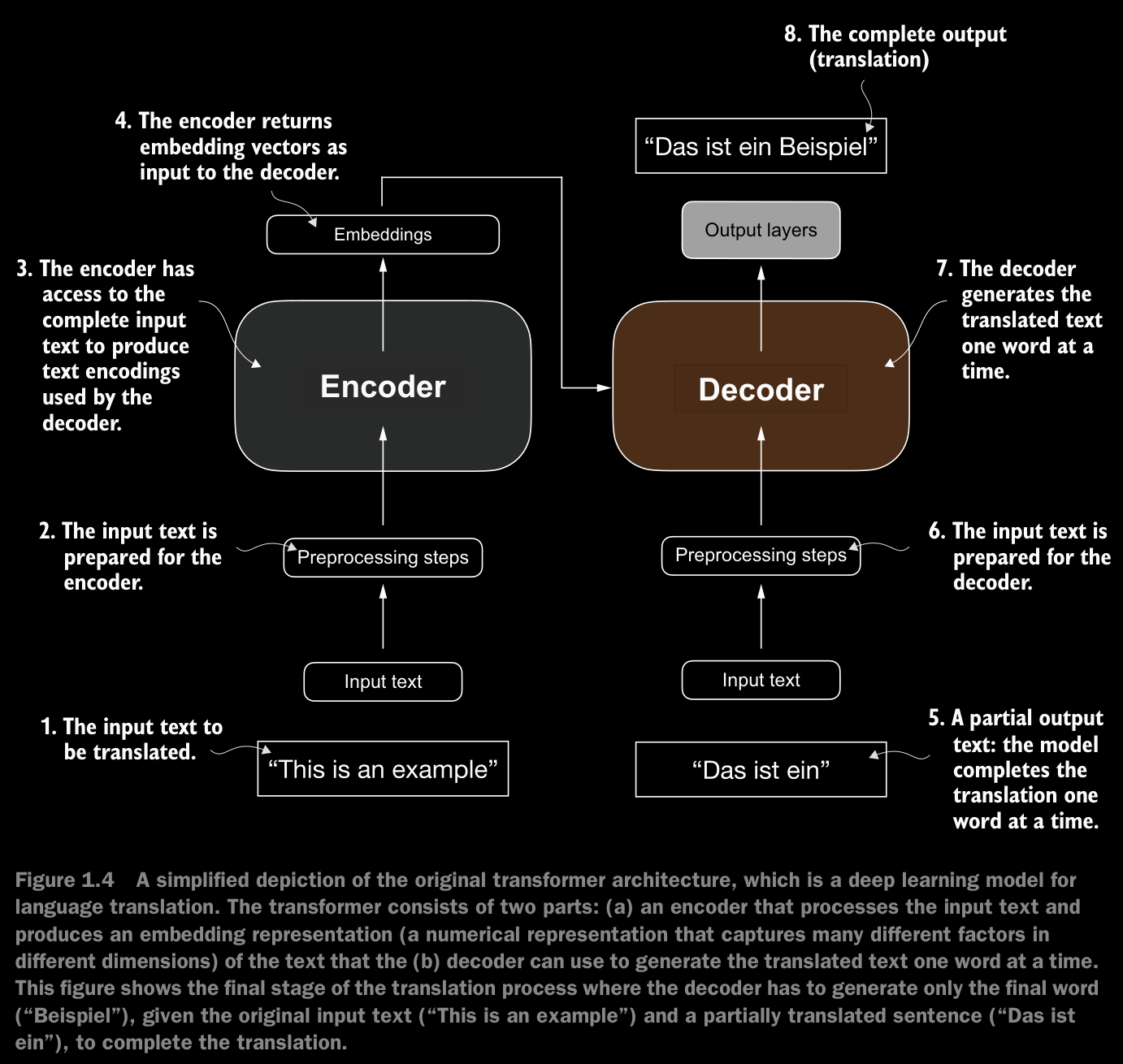
The transformer architecture consists of two submodules: an encoder and a decoder. The encoder module processes the input text and encodes it into a series of numerical representations or vectors that capture the contextual information of the input. Then, the decoder module takes these encoded vectors and generates the output text.
-
Both the encoder and decoder consist of many layers connected by a so-called self-attention mechanism.
-
The self-attention mechanism allows the model to weigh the importance of different words or tokens in a sequence relative to each other. This mechanism enables the model to capture long-range dependencies and contextual relationships within the input data, enhancing its ability to generate coherent and contextually relevant output.
-
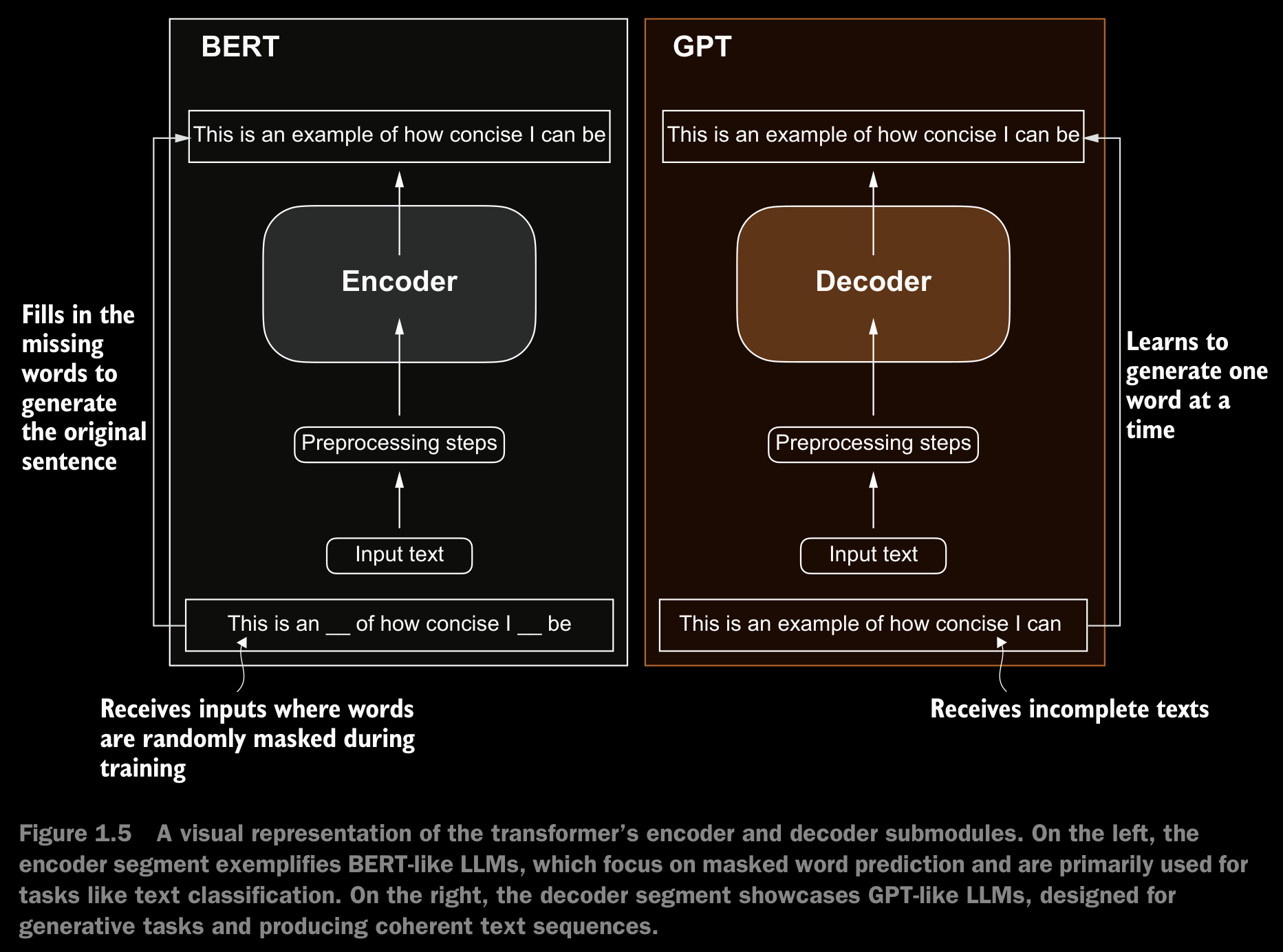
Later variants of the transformer architecture, such as BERT (bidirectional encoder representations from transformers) and the various GPT (generative pretrained transformers) models, built on this concept to adapt this architecture for different tasks.
-
BERT, which is built upon the original transformer’s encoder submodule, differs in its training approach from GPT. While GPT is designed for generative tasks, BERT and its variants specialize in masked word prediction, where the model predicts masked or hidden words in a given sentence. Used in text classification tasks, including sentiment prediction and document categorization.
-
GPT, on the other hand, focuses on the decoder portion of the original transformer architecture and is designed for tasks that require generating texts. This includes machine translation, text summarization, fiction writing, writing computer code, and more.
-
GPT models are adept at executing both zero-shot and few-shot learning tasks.
1.5 Utilizing Large Datasets
- The large training datasets for popular GPT- and BERT-like models represent diverse and comprehensive text corpora encompassing billions of words, which include a vast array of topics and natural and computer languages.
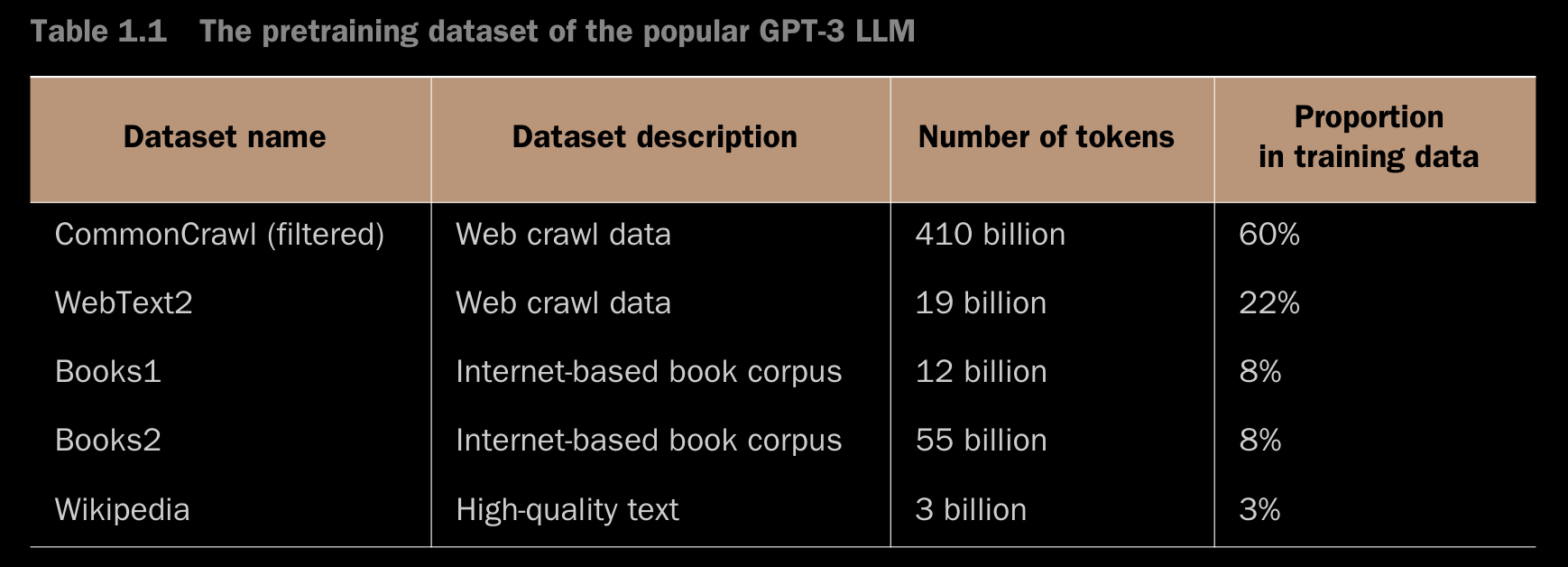
- Although the subsets in the Number of Tokens column total 499 billion, the model was trained on only 300 billion tokens. The authors of the GPT-3 paper did not specify why the model was not trained on all 499 billion tokens.
- later iterations of models like GPT-3, such as Meta’s LLaMA, have expanded their training scope to include additional data sources like Arxiv research papers (92 GB) and StackExchange’s code-related Q&As (78 GB).
- The authors of the GPT-3 paper did not share the training dataset, but a comparable dataset that is publicly available is Dolma: An Open Corpus of Three Trillion Tokens for LLM Pretraining Research by Soldaini et al. 2024 (https://arxiv.org/abs/2402.00159).
1.6 A Closer Look at the GPT Architecture
- GPT was originally introduced in the paper Improving Language Understanding by Generative Pre-Training by Radford et al. from OpenAI.
- GPT-3 is a scaled-up version of this model that has more parameters and was trained on a larger dataset.
- The original model offered in ChatGPT was created by fine-tuning GPT-3 on a large instruction dataset using a method from OpenAI’s InstructGPT paper.
- The next-word prediction task performed by the GPT models is a form of self-supervised learning, which is a form of self-labeling. This means that we don’t need to collect labels for the training data explicitly but can use the structure of the data itself: we can use the next word in a sentence or document as the label that the model is supposed to predict. Since this nextword prediction task allows us to create labels “on the fly,” it is possible to use massive unlabeled text datasets to train LLMs.
- The GPT models are just the decoder part without the encoder in the transformers architecture.
- Since decoder-style models like GPT generate text by predicting text one word at a time, they are considered a type of autoregressive model.
- Architectures such as GPT-3 are also significantly larger than the original transformer model. For instance, the original transformer repeated the encoder and decoder blocks six times. GPT-3 has 96 transformer layers and 175 billion parameters in total.
- GPT models—despite their larger yet simpler decoder-only architecture aimed at next-word prediction—are also capable of performing translation tasks which was the original purpose of the transformer architecture. This capability was initially unexpected to researchers, as it emerged from a model primarily trained on a next-word prediction task, which is a task that did not specifically target translation.
- The ability to perform tasks that the model wasn’t explicitly trained to perform is called an emergent behavior.
- The fact that GPT models can “learn” the translation patterns between languages and perform translation tasks even though they weren’t specifically trained for it demonstrates the benefits and capabilities of these large-scale, generative language models. We can perform diverse tasks without using diverse models for each.
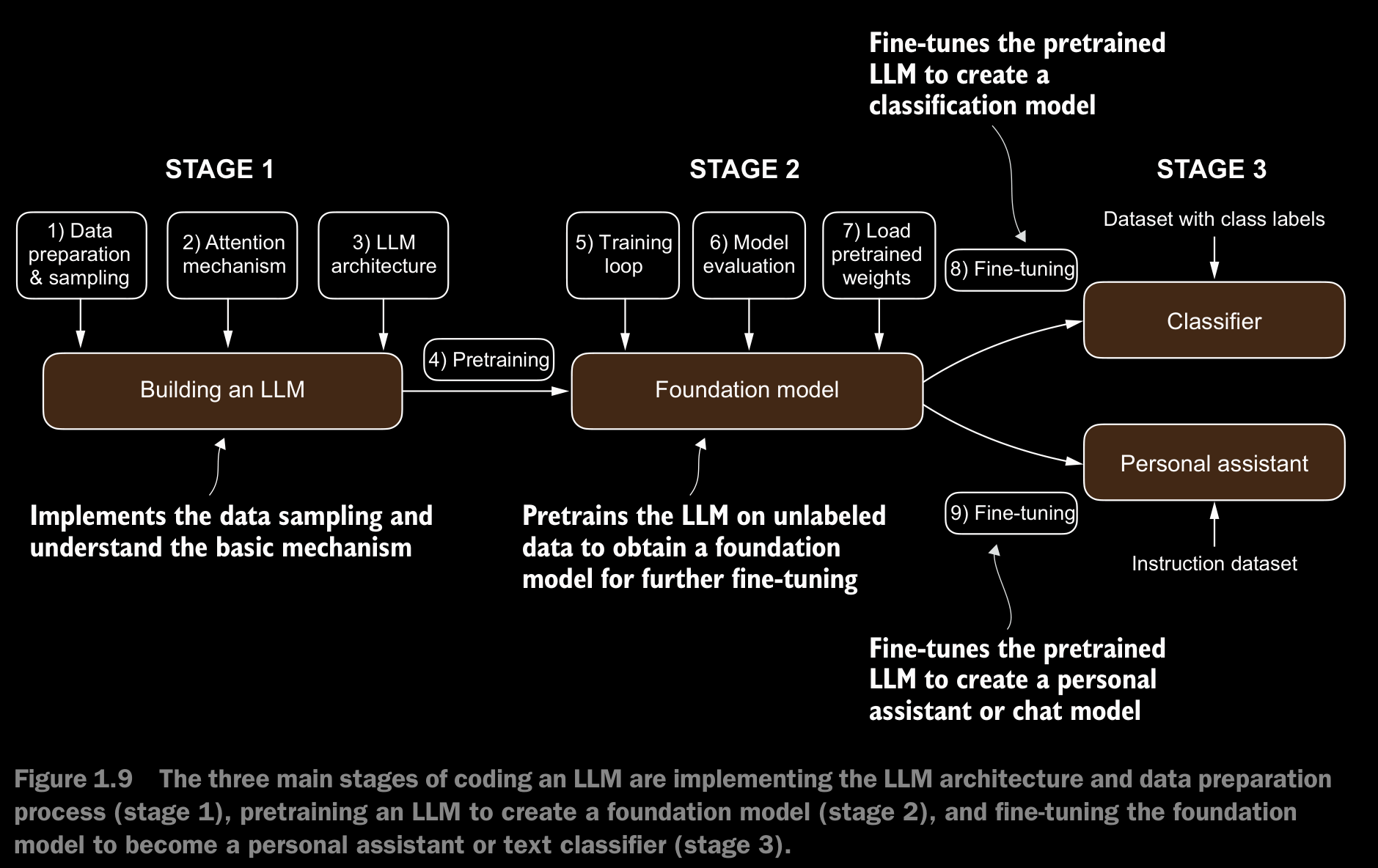
1.7 Building a Large Language Model