5.1 Evaluating Generative Text Models
5.1.1 Usign GPT to Generate Text
- In the code implementaion, the context length is changed from 1024 to 256. This is to make the model capable of running in normal laptops/PCs.
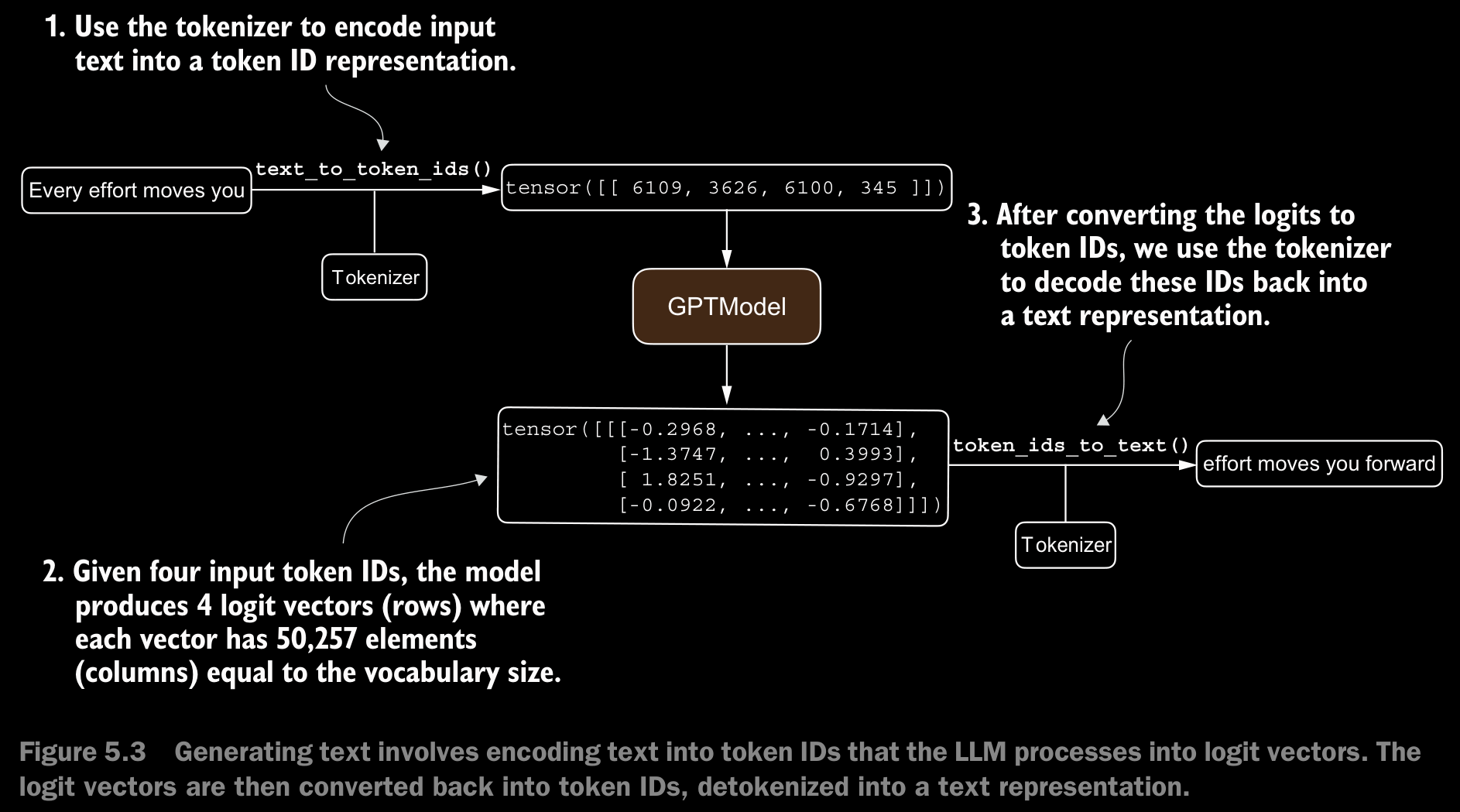
- To define what makes text “coherent” or “high quality,” we have to implement a numerical method to evaluate the generated content. This approach will enable us to monitor and enhance the model’s performance throughout its training process.
5.1.2 Calculating the Text Generation Loss
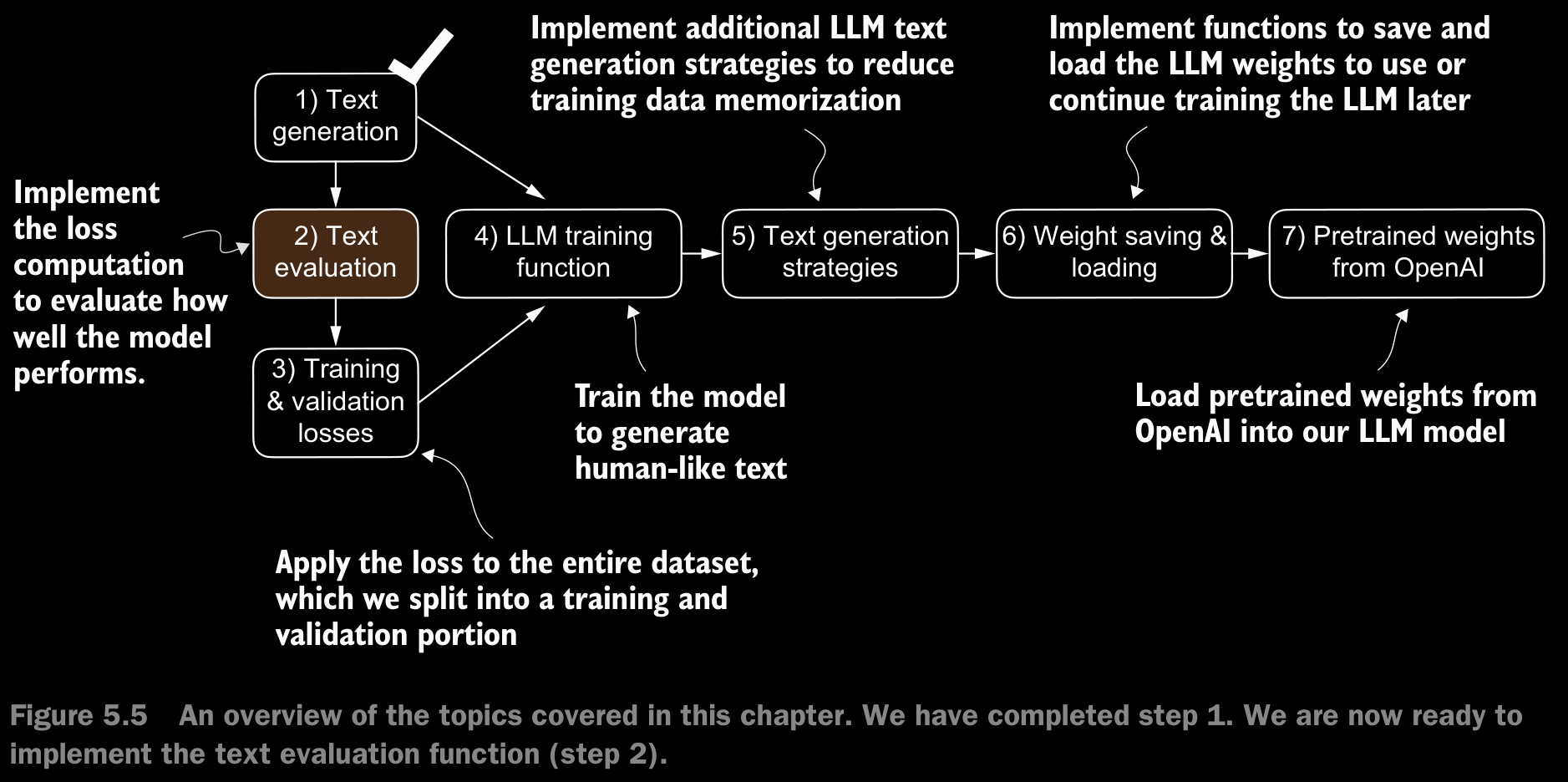
- The model training aims to increase the softmax probability in the index positions corresponding to the correct target token IDs.

- Working with logarithms of probability scores is more manageable in mathematical optimization than handling the scores directly.
- In the context of machine learning and specifically in frameworks like PyTorch, the cross_entropy function computes this measure for discrete outcomes, which is similar to the negative average log probability of the target tokens given the model’s generated token probabilities, making the terms “cross entropy” and “negative average log probability” related and often used interchangeably in practice.
Perplexity:
- Perplexity is a measure often used alongside cross entropy loss to evaluate the performance of models in tasks like language modeling. It can provide a more interpretable way to understand the uncertainty of a model in predicting the next token in a sequence.
- Perplexity measures how well the probability distribution predicted by the model matches the actual distribution of the words in the dataset. Similar to the loss, a lower perplexity indicates that the model predictions are closer to the actual distribution.
- Perplexity can be calculated as
perplexity = torch.exp(loss). - Perplexity is often considered more interpretable than the raw loss value because it signifies the effective vocabulary size about which the model is uncertain at each step.
- For example, let
perplexity = tensor(48725.8203). This would translate to the model being unsure about which among48,725tokens in the vocabulary to generate as the next token.
5.1.3 Calculating the Training and Validation Set Losses
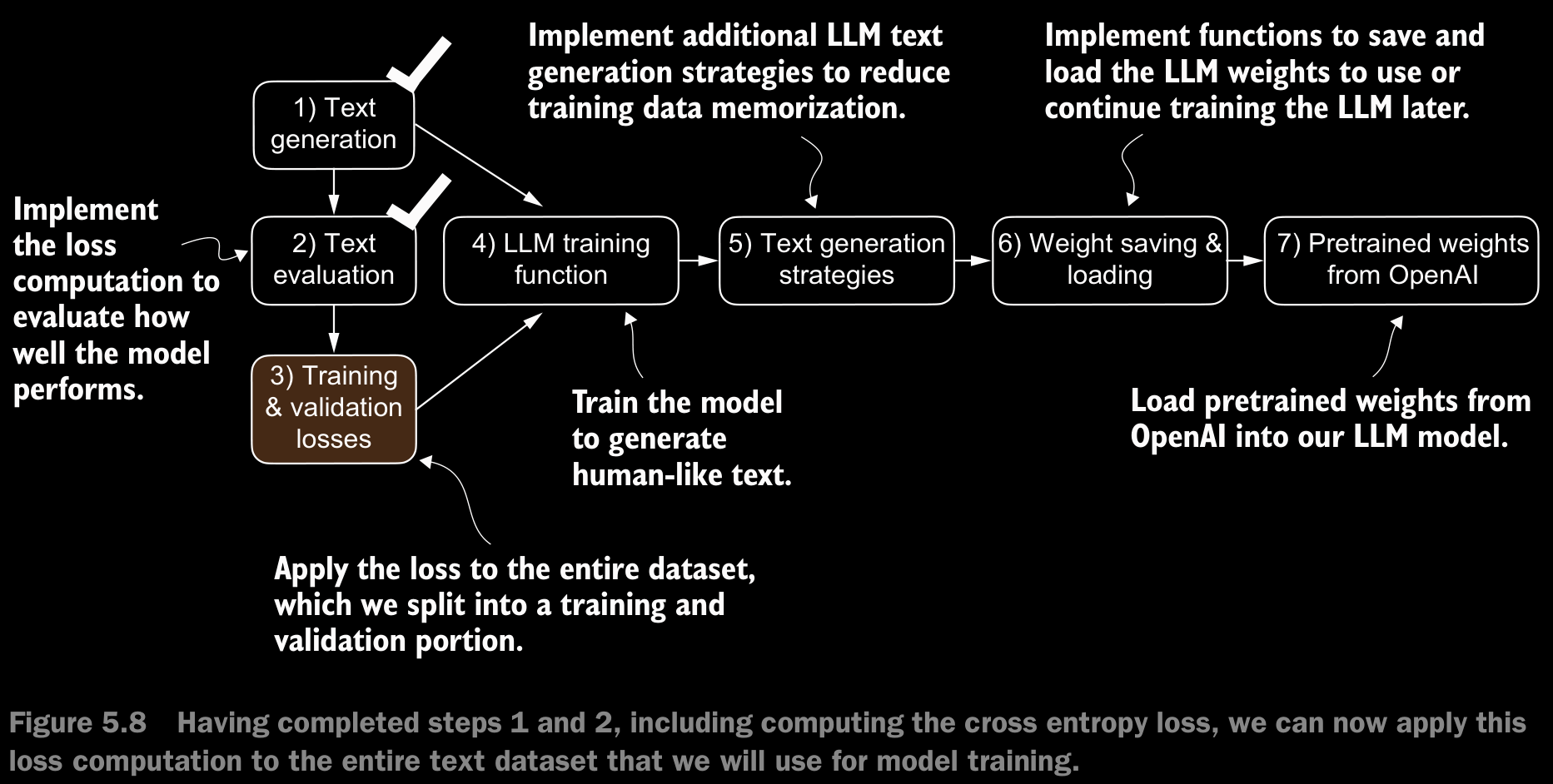
- For educational purposes, we will use “The Verdict” as our dataset. This makes is so that, we can run the model on standard laptops without needing high-end GPUs
Interested readers can also use the supplementary code for this book to prepare a larger-scale dataset consisting of more than 60,000 public domain books from Project Gutenberg and train an LLM on these (see appendix D for details).

- In figure 5.9. Due to spatial constraints, we use a
max_length=6. However, for the actual data loaders, we set themax_lengthequal to the 256-token context length that the LLM supports so that the LLM sees longer texts during training.
5.2 Training an LLM
Interested readers can learn about more advanced techniques, including learning rate warmup, cosine annealing, and gradient clipping, in appendix D.
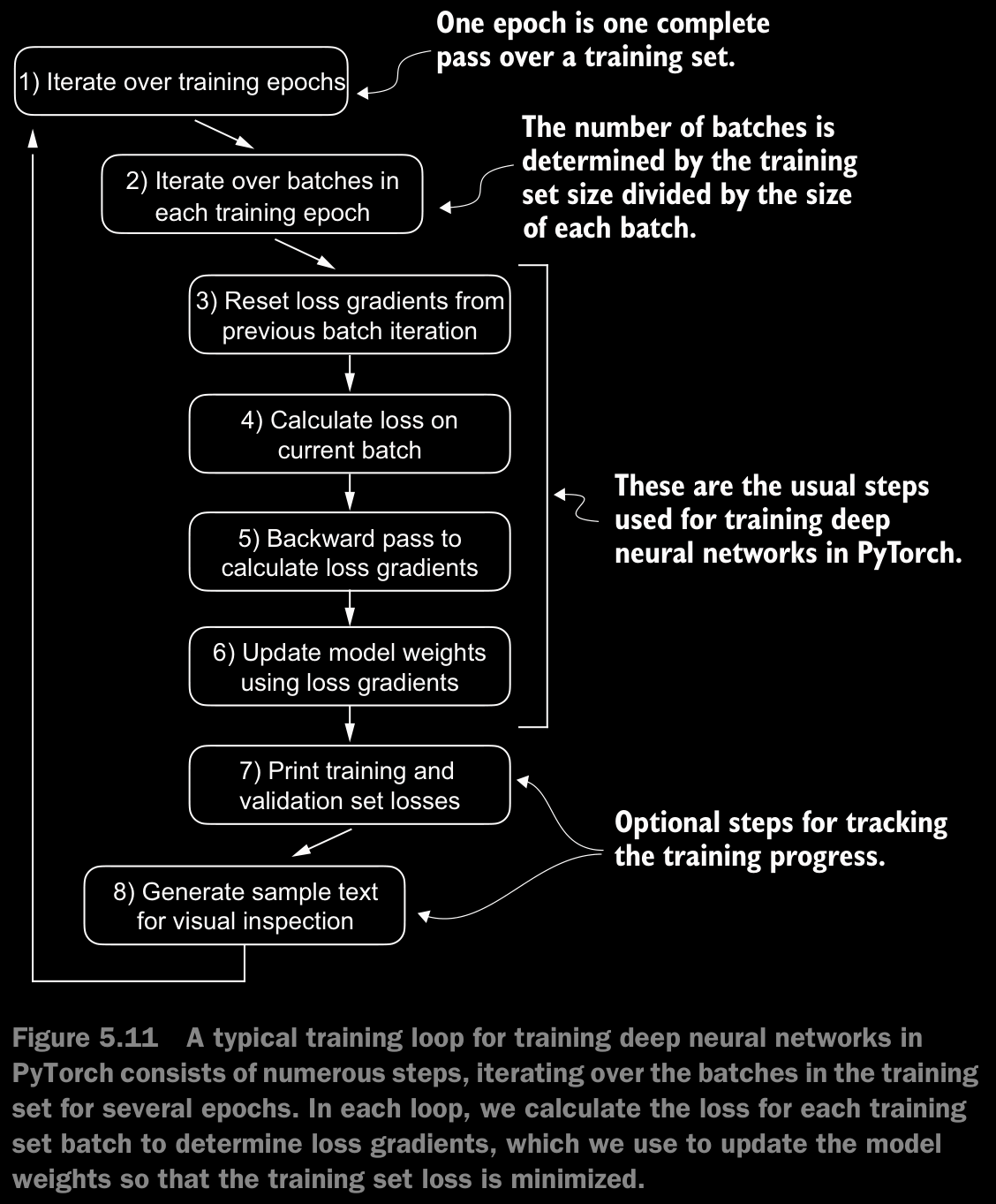
- Here, AdamW is used as an optimizer. This is a variant of the famous Adam optimizer that improves the weight decay approach, which aims to minimize model complexity and prevent overfitting by penalizing larger weights. This achives more effective regularization and thus better generalization and lessen the tendency to overfit.
- Generally, AdamW is used as the optimizer while training LLMs.
- In the run, we get the following graph
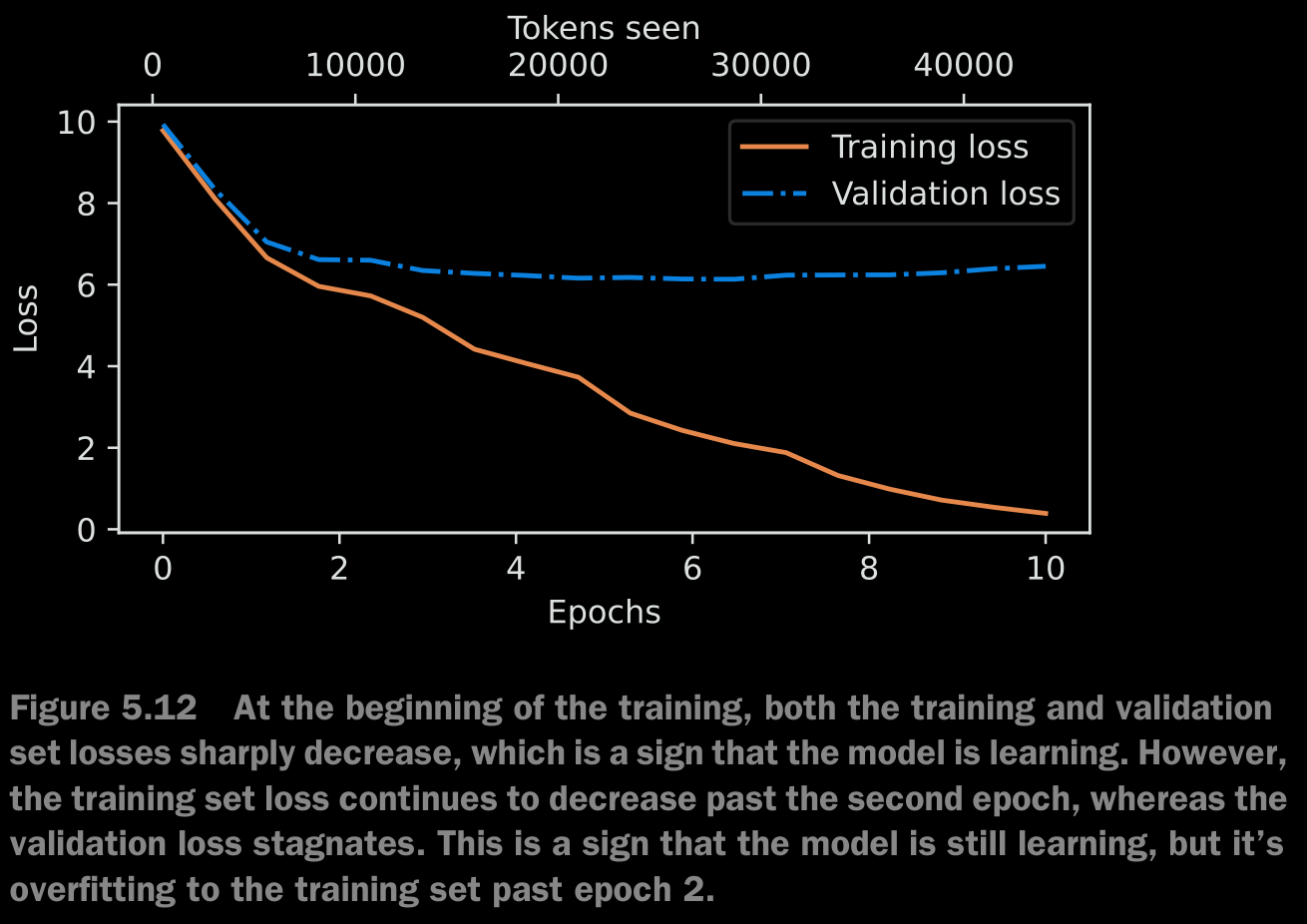
- This memorization is expected since we are working with a very, very small training dataset and training the model for multiple epochs. Usually, it’s common to train a model on a much larger dataset for only one epoch.
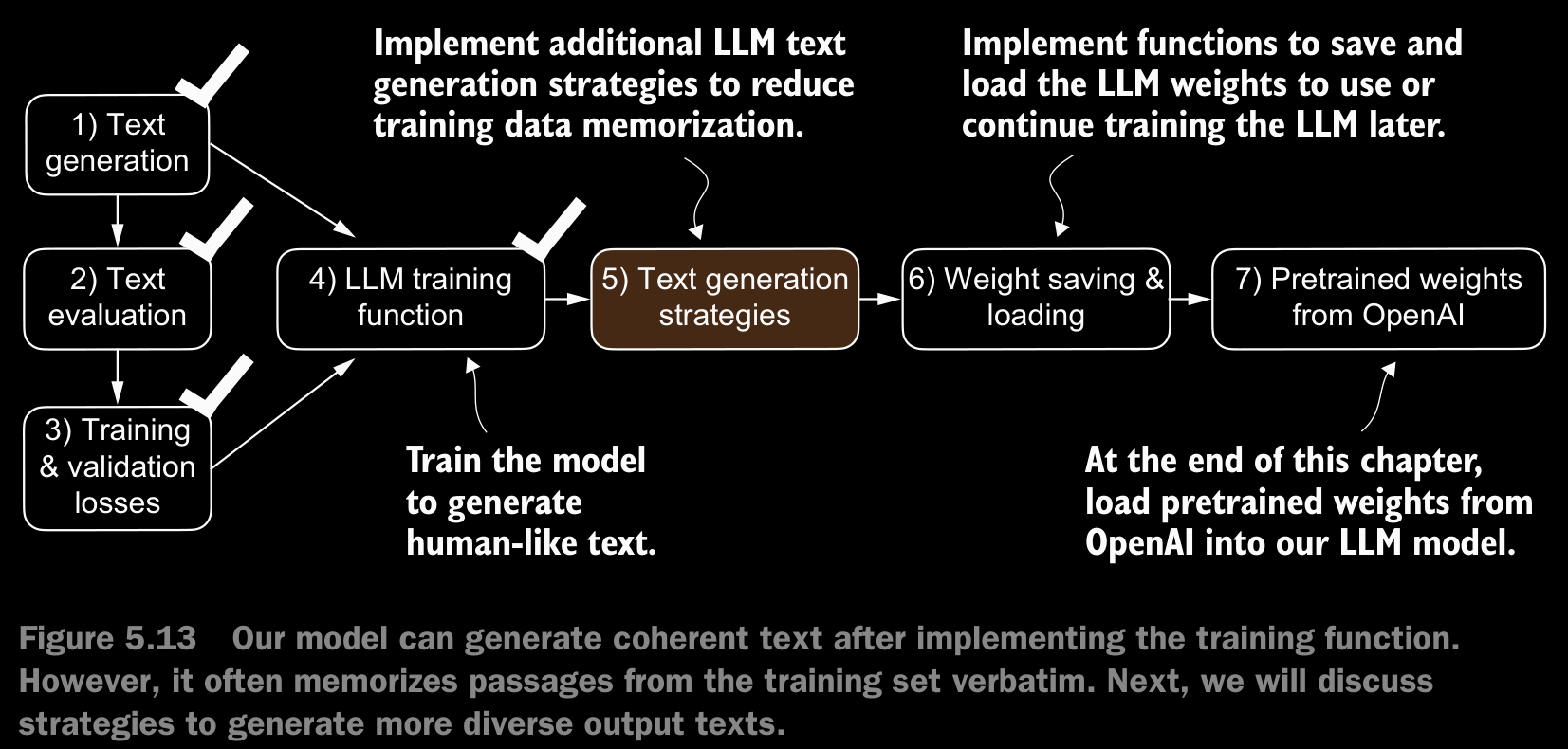
5.3 Decoding Strategies to Control Randomness
- Text generation strategies == decoding strategies
- The generated token is selected at each generation step corresponding to the largest probability score among all tokens in the vocabulary. This means that the LLM will always generate the same outputs even if we run the preceding
generate_text_simplefunction multiple times on the same start context.
5.3.1 Temperature Scaling
- Temperature Scaling is a technique that adds a probabilistic selection process to the next-token generation task.
- Previously, inside the
generate_text_simplefunction, we always sampled the token with the highest probability as the next token usingtorch.argmax, also known as greedy decoding. To generate text with more variety, we can replace argmax with a function that samples from a probability distribution (here, the probability scores the LLM generates for each vocabulary entry at each token generation step).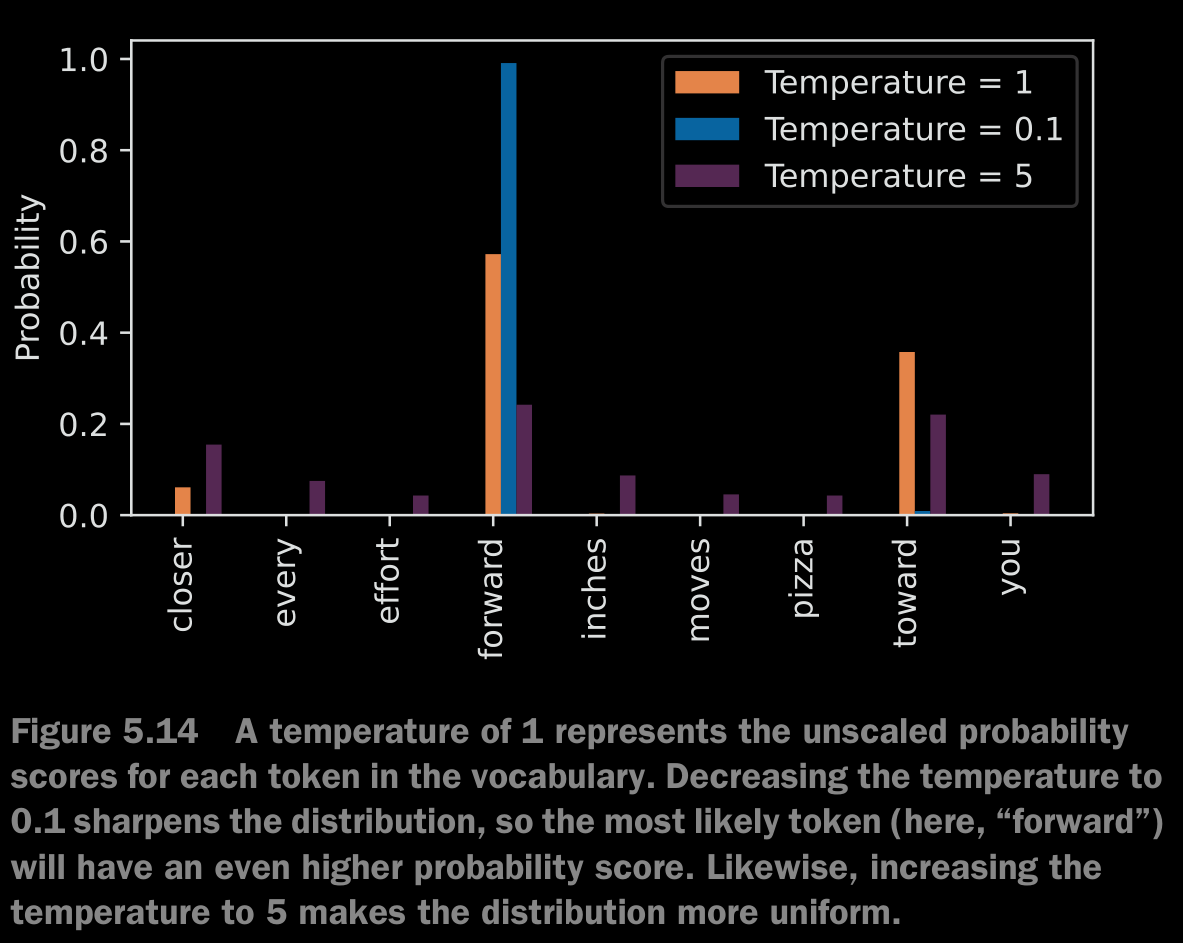
- More details in the code
- Higher temperature values result in more uniformly distributed next-token probabilities, which result in more diverse outputs as it reduces the likelihood of the model repeatedly selecting the most probable token.
- This method allows for the exploring of less likely but potentially more interesting and creative paths in the generation process.
- One down side of this approach is that it sometimes leads to grammatically incorrect or completely nonsensical outputs.
5.3.2 Top-k Sampling
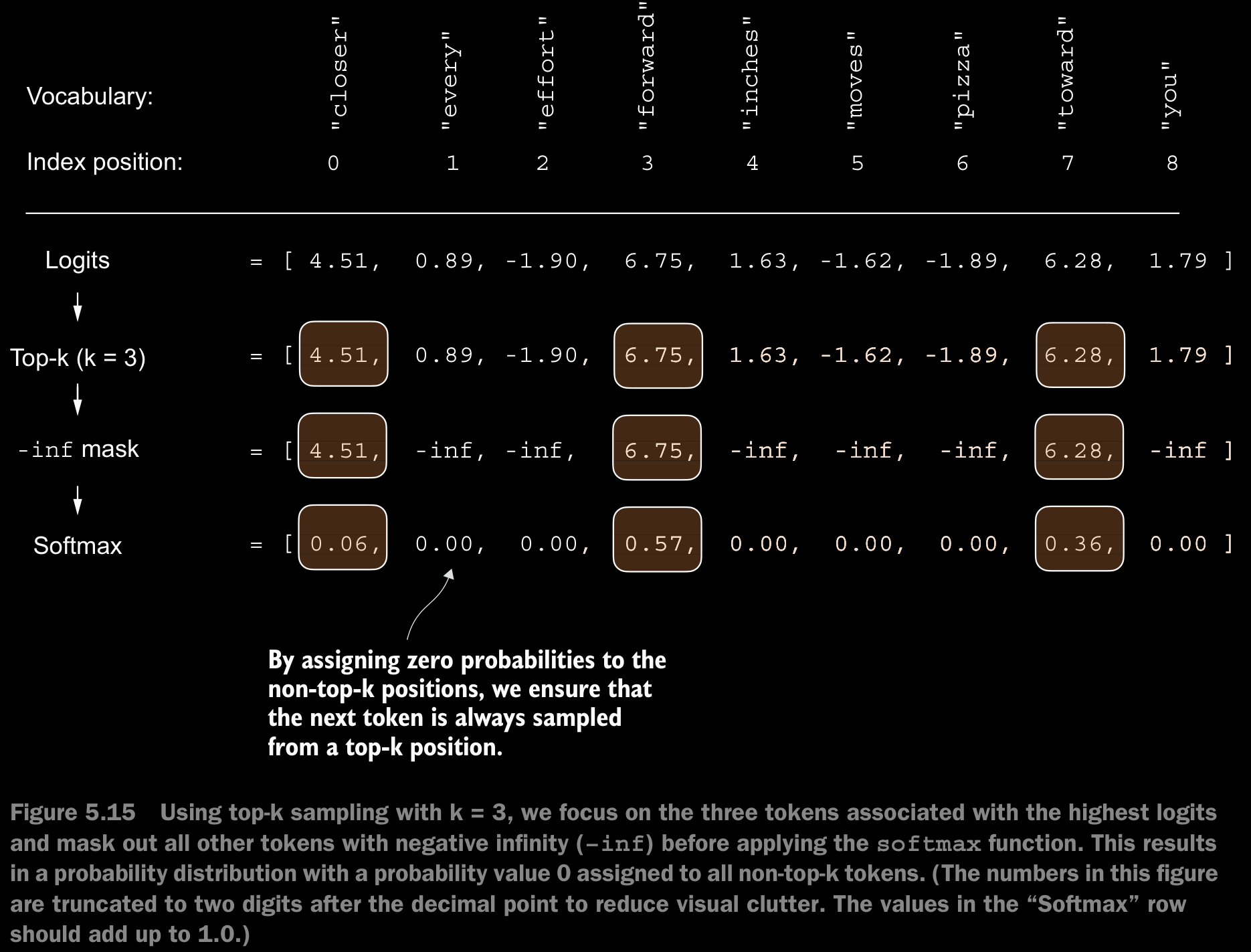
- Top-k Sampling in combination with probabilistic sampling and temperature scaling, can improve the text generation results. This directly addresses the down side of Temperature Scaling on its own.
- Here, we can restrict the sampled tokens to top-k most likely tokens and exclude all other tokens from the selection process by masking their probability scores.
5.3.3 Modifying the Text Generation Function
- Combining temperature sampling and top-k sampling to modify the
generate_ text_simplefunction we used to generate text via the LLM earlier. - More in code
5.4 Loading and Saving Model Weights in Pytorch
- Adaptive optimizers such as AdamW store additional parameters for each model eight. AdamW uses historical data to adjust learning rates for each model parameter dynamically. Without it, the optimizer resets, and the model may learn suboptimally or even fail to converge properly, which means it will lose the ability to generate coherent text. Using
torch.save, we can save both the model and optimizerstate_dictcontents
5.5 Loading Pretrained Weights from OpenAI