2.1 Understanding Word Embeddings
- The concept of converting data into a vector format is often referred to as embedding.
- At its core, an embedding is a mapping from discrete objects, such as words, images, or even entire documents, to points in a continuous vector space—the primary purpose of embeddings is to convert nonnumeric data into a format that neural networks can process.
- While word embeddings are the most common form of text embedding, there are also embeddings for sentences, paragraphs, or whole documents.
- Sentence or paragraph embeddings are popular choices for retrieval-augmented generation - RAG.
- Retrieval-augmented generation combines generation (like producing text) with retrieval (like searching an external knowledge base) to pull relevant information when generating text.
- Since our goal is to train GPT-like LLMs, which learn to generate text one word(sub-word token) at a time, we will focus on word embeddings.
- One of the earlier and most popular embedding approach is the Word2Vec approach.
- The main idea behind Word2Vec is that words that appear in similar contexts tend to have similar meanings. Consequently, when projected into two-dimensional word embeddings for visualization purposes, similar terms are clustered together.
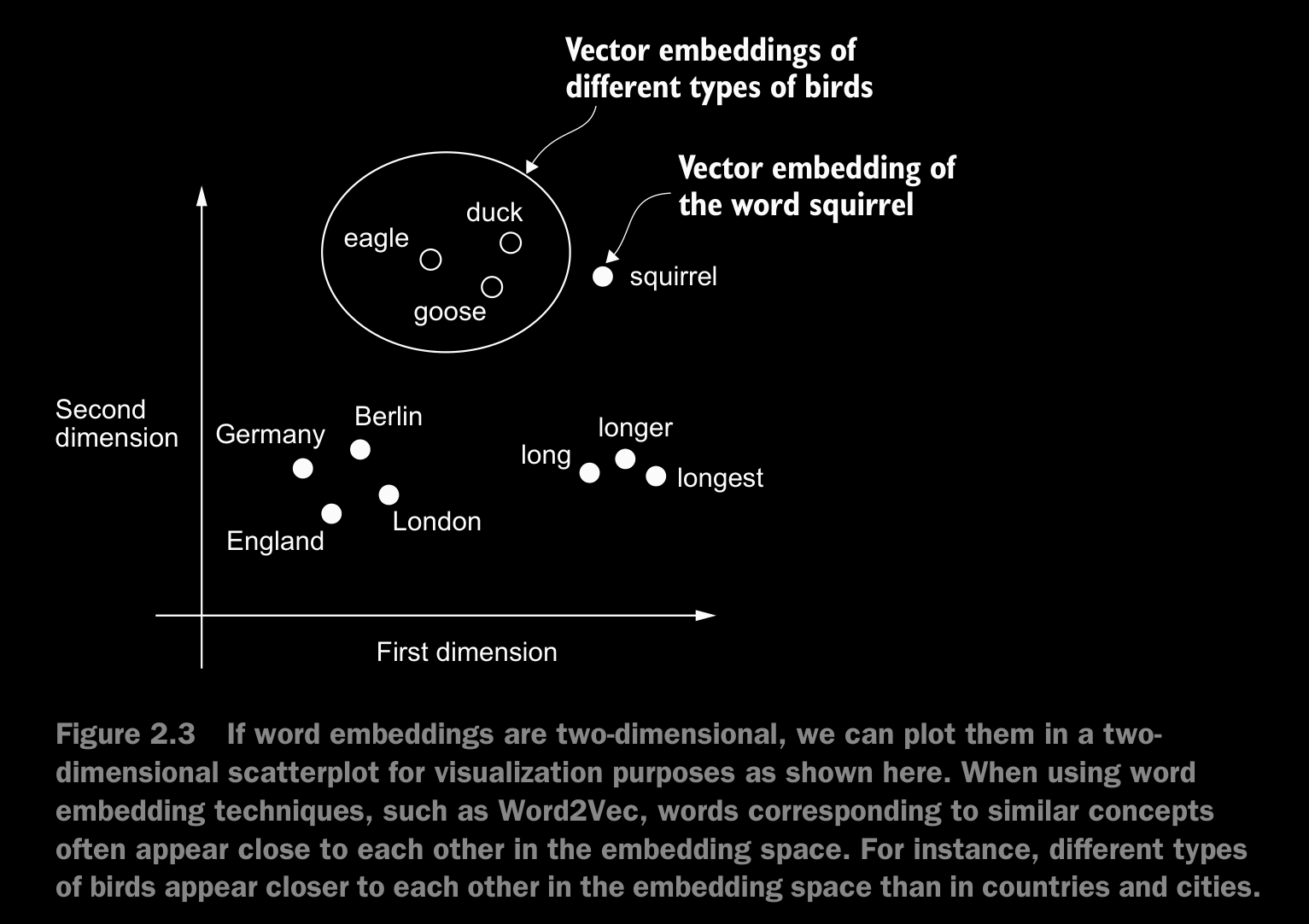
- Word embeddings can have varying dimensions. A higher dimensionality might capture more nuanced relationships but at the cost of computational efficiency.
- While we can use pretrained models such as Word2Vec to generate embeddings for machine learning models, LLMs commonly produce their own embeddings that are part of the input layer and are updated during training.
- The advantage of optimizing the embeddings as part of the LLM training instead of using Word2Vec is that the embeddings are optimized to the specific task and data at hand.
- For both GPT-2 and GPT-3, the embedding size (often referred to as the dimensionality of the model’s hidden states) varies based on the specific model variant and size. It is a tradeoff between performance and efficiency. The smallest GPT-2 models (117M and 125M parameters) use an embedding size of 768 dimensions. The largest GPT-3 model (175B parameters) uses an embedding size of 12,288 dimensions.
2.2 Tokenizing Text
- The tokenization scheme which seperates words based on white space mostly works for separating the example text into individual words; however, some words are still connected to punctuation characters that we want to have as separate list entries.
- We refrain from making all text lowercase because capitalization helps LLMs distinguish between proper nouns and common nouns, understand sentence structure, and learn to generate text with proper capitalization.
- When developing a simple tokenizer, whether we should encode whitespaces as separate characters or just remove them depends on our application and its requirements. Removing whitespaces reduces the memory and computing requirements. However, keeping whitespaces can be useful if we train models that are sensitive to the exact structure of the text (for example, Python code, which is sensitive to indentation and spacing). Here, we remove whitespaces for simplicity and brevity of the tokenized outputs. Later, we will switch to a tokenization scheme that includes whitespaces.
2.3 Converting tokens into token IDs
- The tokens created will then be converted from a Python string to an integer representation to produce the token IDs. This conversion is an intermediate step before converting the token IDs into embedding vectors.
- To map the previously generated tokens into token IDs, we have to build a vocabulary first. This vocabulary defines how we map each unique word and special character to a unique integer. The details on how the vocabulary is made is in the code.
- the vocabulary which is a dictionary contains individual tokens associated with unique integer labels. Our goal is to apply this vocabulary to convert new text into token IDs.
- When we want to convert the outputs of an LLM from numbers back into text, we need a way to turn token IDs into text. For this, we can create an inverse version of the vocabulary that maps token IDs back to the corresponding text tokens.
2.4 Adding special context tokens
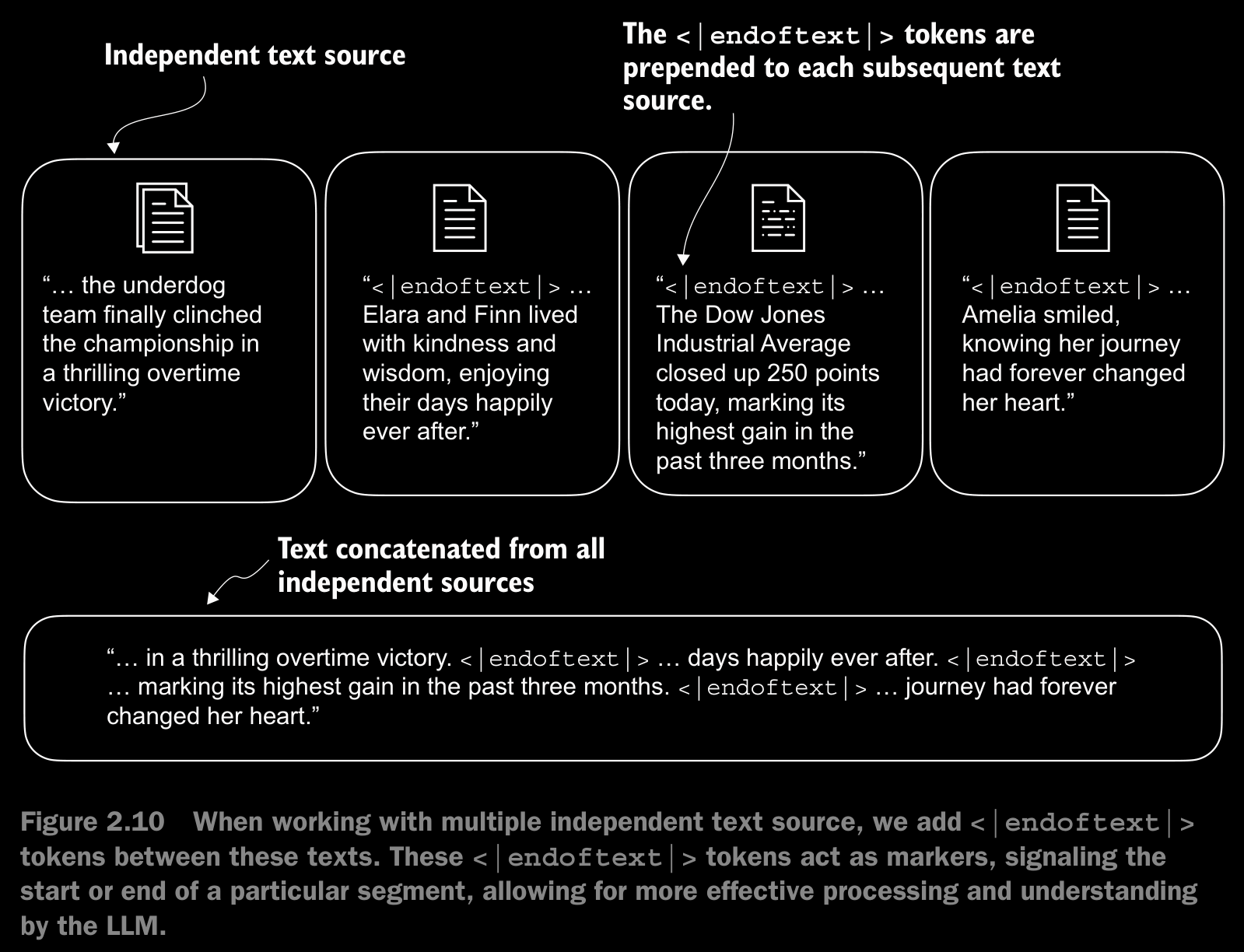
- We need to modify the tokenizer to handle unknown words. We also need to address the usage and addition of special context tokens that can enhance a model’s understanding of context or other relevant information in the text. These special tokens can include markers for unknown words and document boundaries.
- We will modify the vocabulary and tokenizer, SimpleTokenizerV2, to support two new tokens, <|unk|> and <|endoftext|>
- The <|endoftext|> token helps the LLM understand that although these text sources are concatenated for training, they are, in fact, unrelated.
- Depending on the LLM, some researchers also consider additional special tokens
such as the following:
[BOS](beginning of sequence)—This token marks the start of a text. It signifies to the LLM where a piece of content begins.[EOS](end of sequence)—This token is positioned at the end of a text and is especially useful when concatenating multiple unrelated texts, similar to <|endoftext|>. For instance, when combining two different Wikipedia articles or books, the[EOS]token indicates where one ends and the next begins.[PAD](padding)—When training LLMs with batch sizes larger than one, the batch might contain texts of varying lengths. To ensure all texts have the same length, the shorter texts are extended or “padded” using the[PAD]token, up to the length of the longest text in the batch.
- The tokenizer used for GPT models does not need any of these tokens; it only uses an <|endoftext|> token for simplicity. <|endoftext|> is analogous to the
[EOS]token. <|endoftext|> is also used for padding. - Typically a mask is used, meaning padded tokens are not attended to. Thus, the specific token chosen for padding becomes inconsequential.
- The tokenizer used for GPT models doesn’t use an <|unk|> token for out-of-vocabulary words. Instead, GPT models use a byte pair encoding tokenizer, which breaks words down into subword units.
2.5 Byte Pair Encoding (BPE)
- The BPE tokenizer was used to train LLMs such as GPT-2, GPT-3, and the original model used in ChatGPT.
- Since implementing BPE can be relatively complicated, we will use an existing Python open source library called tiktoken which is written in rust making it efficient.
- The BPE tokenizer has a total vocabulary size of 50,257, with <|endoftext|> being assigned the largest token ID.
- the BPE tokenizer encodes and decodes unknown words correctly. The BPE tokenizer can handle any unknown word.
- The algorithm underlying BPE breaks down words that aren’t in its predefined vocabulary into smaller subword units or even individual characters, enabling it to handle out-of-vocabulary words. So, thanks to the BPE algorithm, if the tokenizer encounters an unfamiliar word during tokenization, it can represent it as a sequence of subword tokens or characters.
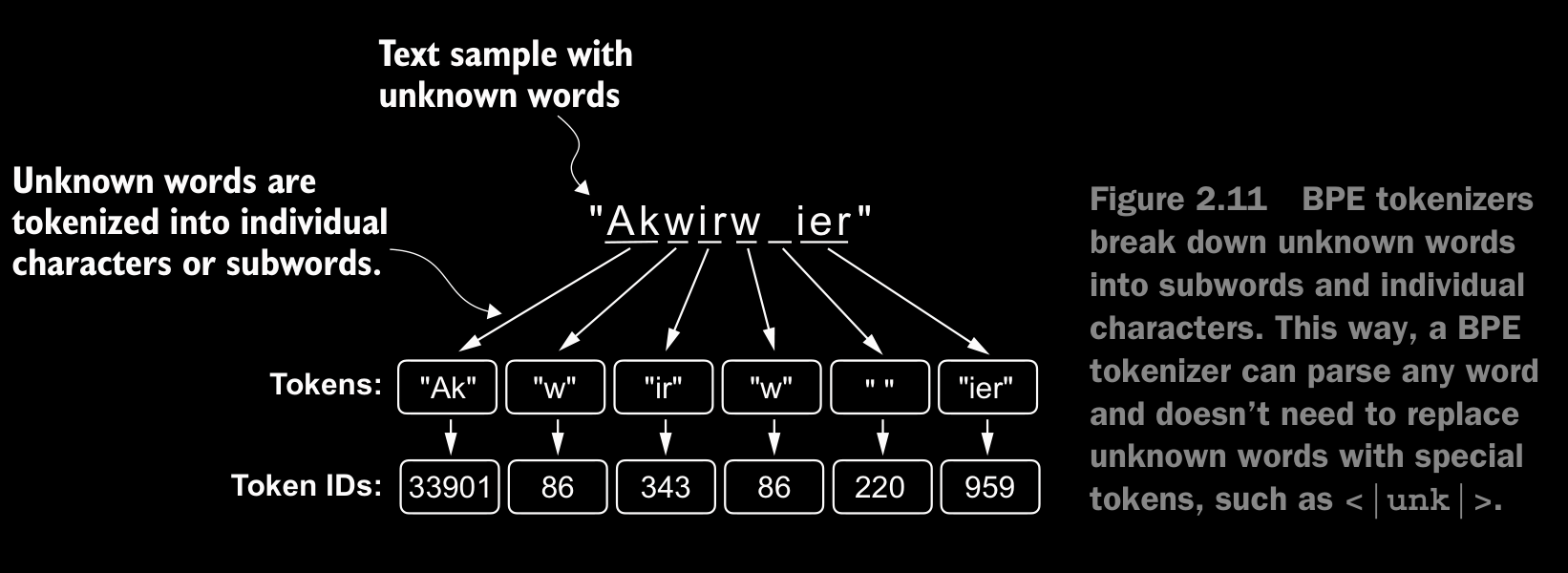
- BPE builds its vocabulary by iteratively merging frequent characters into subwords and frequent subwords into words.
- For example, BPE starts with adding all individual single characters to its vocabulary (“a,” “b,” etc.). In the next stage, it merges character combinations that frequently occur together into subwords. For example,“d” and “e” may be merged into the subword “de,” which is common in English.
2.6 Data Sampling with a Sliding Window
- The next step in creating the embeddings for the LLM is to generate the input–target pairs required for training an LLM.


- While the figure shows the tokens in string format for illustration purposes, the code implementation will operate on token IDs directly since the encode method of the BPE tokenizer performs both tokenization and conversion into token IDs as a single step.
- further implementation details in the jupyter notebook
2.7 Creating Token Embeddings
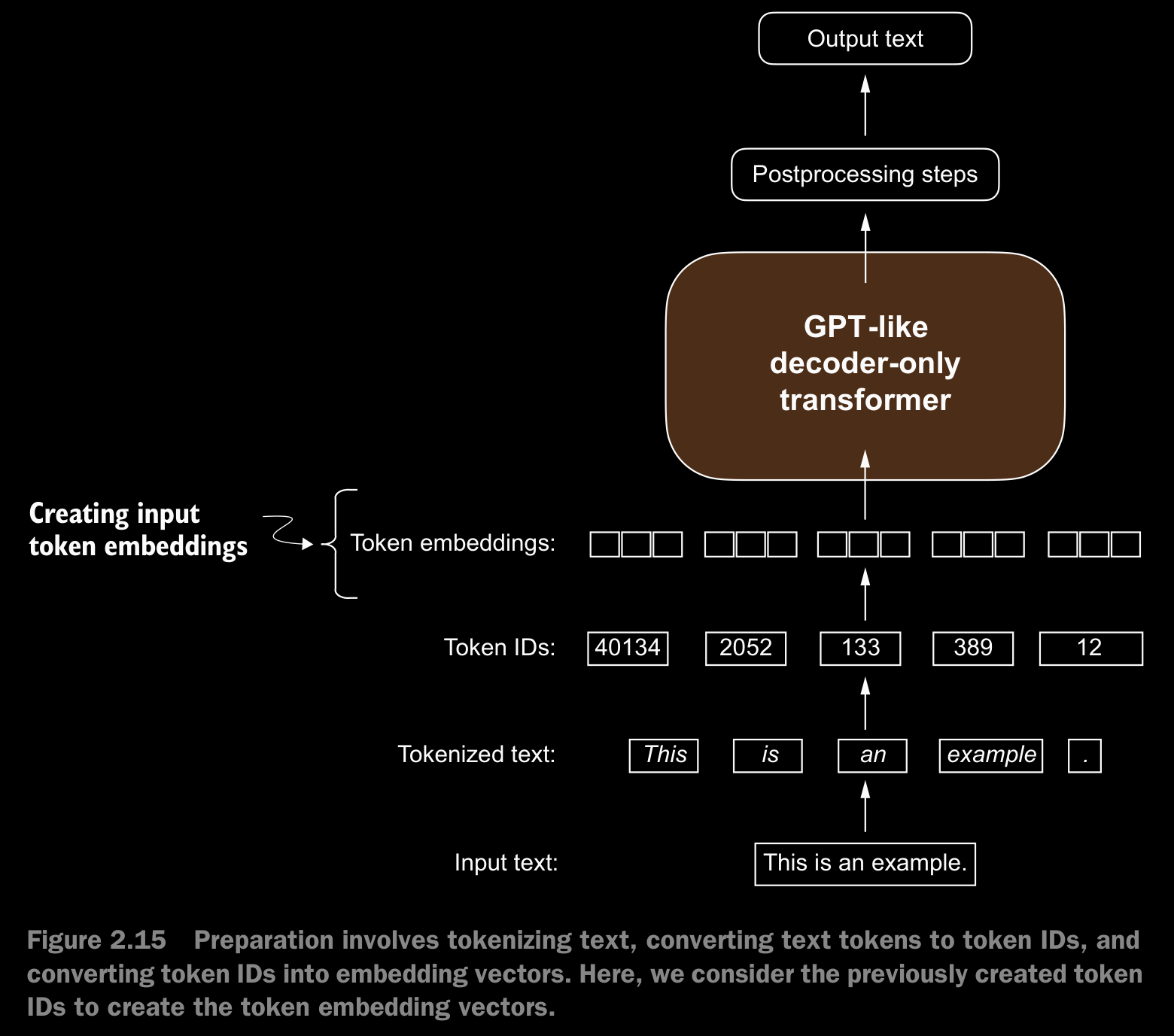
- As a preliminary step, we must initialize these embedding weights with random values. This initialization serves as the starting point for the LLM’s learning process. In chapter 5, we will optimize the embedding weights as part of the LLM training.
- A continuous vector representation, or embedding, is necessary since GPT-like LLMs are deep neural networks trained with the backpropagation algorithm.
- futher details in the jupyter notebook
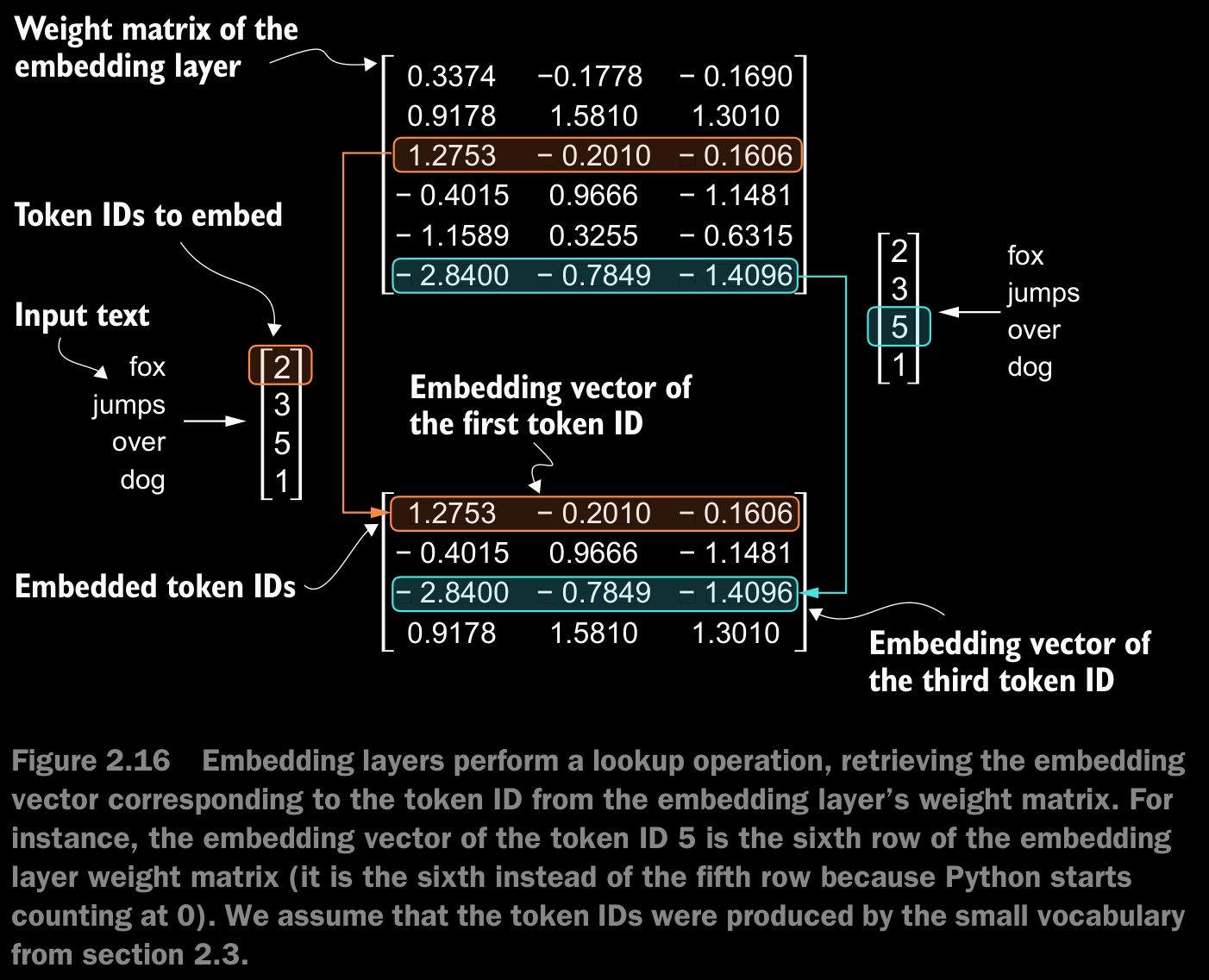
- The embedding layer in PyTorch is essentially a lookup operation that retrieves rows from the embedding layer’s weight matrix via a token ID.
- the embedding layer approach described here is essentially just a more efficient way of implementing one-hot encoding followed by matrix multiplication in a fully connected layer, which is illustrated in the supplementary code on GitHub at https://mng.bz/ZEB5. Because the embedding layer is just a more efficient implementation equivalent to the one-hot encoding and matrix-multiplication approach, it can be seen as a neural network layer that can be optimized via backpropagation.
Initialization of Embedding Weights
- Random Initialization:
- The weights of the embedding layer are initialized randomly at the beginning of training.
- These weights serve as the starting point for learning meaningful representations during the training process.
- Optimization:
- The embedding weights are adjusted via backpropagation during the model training phase.
- This allows the embeddings to capture semantic properties of the tokens.
Embedding Vectors
- Continuous Representation:
- An embedding vector is a continuous, dense vector that represents a token.
- Example: In GPT-3, each embedding vector has 12,288 dimensions.
- Why Embeddings?:
- Neural networks require numerical inputs for learning.
- Embeddings map discrete tokens to high-dimensional vectors, capturing meaningful relationships between words.
Example in PyTorch
- Defining Input Token IDs:
input_ids = torch.tensor([2, 3, 5, 1])This represents four tokens with IDs: **2, 3, 5, and 1**.
2. Setting Vocabulary Size and Embedding Dimension:
vocab_size = 6 # Assume a small vocabulary of 6 words
output_dim = 3 # Each token will be represented by a 3-dimensional vector- Initializing Embedding Layer:
torch.manual_seed(123) # For reproducibility
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
print(embedding_layer.weight)Sample Output:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)- The weight matrix has 6 rows (one for each token in the vocabulary) and 3 columns (the embedding dimensions).
- Obtaining the Embedding for a Single Token:
print(embedding_layer(torch.tensor([3])))Output:
tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=<EmbeddingBackward0>)- The result is the embedding vector for token ID 3, corresponding to the fourth row of the weight matrix (zero-indexed).
- Obtaining Embeddings for Multiple Tokens:
print(embedding_layer(input_ids))Output:
tensor([[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-2.8400, -0.7849, -1.4096],
[ 0.9178, 1.5810, 1.3010]], grad_fn=<EmbeddingBackward0>)-
Each row corresponds to the embedding vector of a token in the input list
[2, 3, 5, 1]. -
Positional Encoding: After creating token embeddings, positional information is typically added to encode the order of tokens in the sequence. This ensures the model can distinguish between different positions within the text.
2.8 Encoding Word Positions
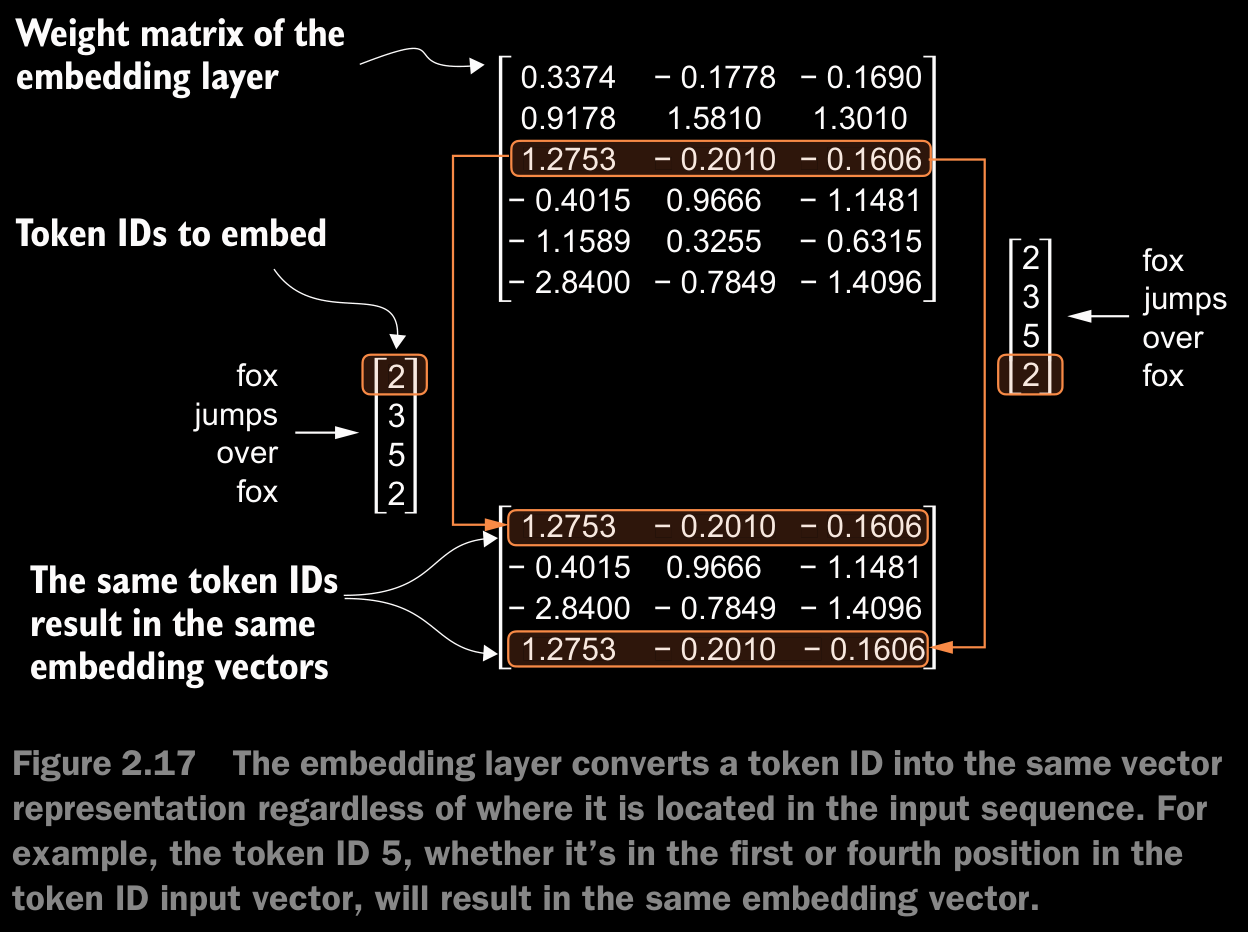
- token embeddings are a suitable input for an LLM. However, a minor shortcoming of LLMs is that their self-attention mechanism doesn’t have a notion of position or order for the tokens within a sequence.
- The way the previously introduced embedding layer works is that the same token ID always gets mapped to the same vector representation, regardless of where the token ID is positioned in the input sequence
- To achieve this, we can use two broad categories of position-aware embeddings:
- relative positional embeddings and
- absolute positional embeddings.
- Absolute positional embeddings are directly associated with specific positions in a sequence. For each position in the input sequence, a unique embedding is added to the token’s embedding to convey its exact location. For instance, the first token will have a specific positional embedding, the second token another distinct embedding, and so on. (fig 2.18)

- Instead of focusing on the absolute position of a token, the emphasis of relative positional embeddings is on the relative position or distance between tokens. This means the model learns the relationships in terms of “how far apart” rather than “at which exact position.” The advantage here is that the model can generalize better to sequences of varying lengths, even if it hasn’t seen such lengths during training.
- The choice between them often depends on the specific application and the nature of the data being processed.
- OpenAI’s GPT models use absolute positional embeddings that are optimized during the training process rather than being fixed or predefined like the positional encodings in the original transformer model. This optimization process is part of the model training itself.
- In this section, we will create the initial positional embeddings to create the LLM inputs.
- further details in the jupyter notebook