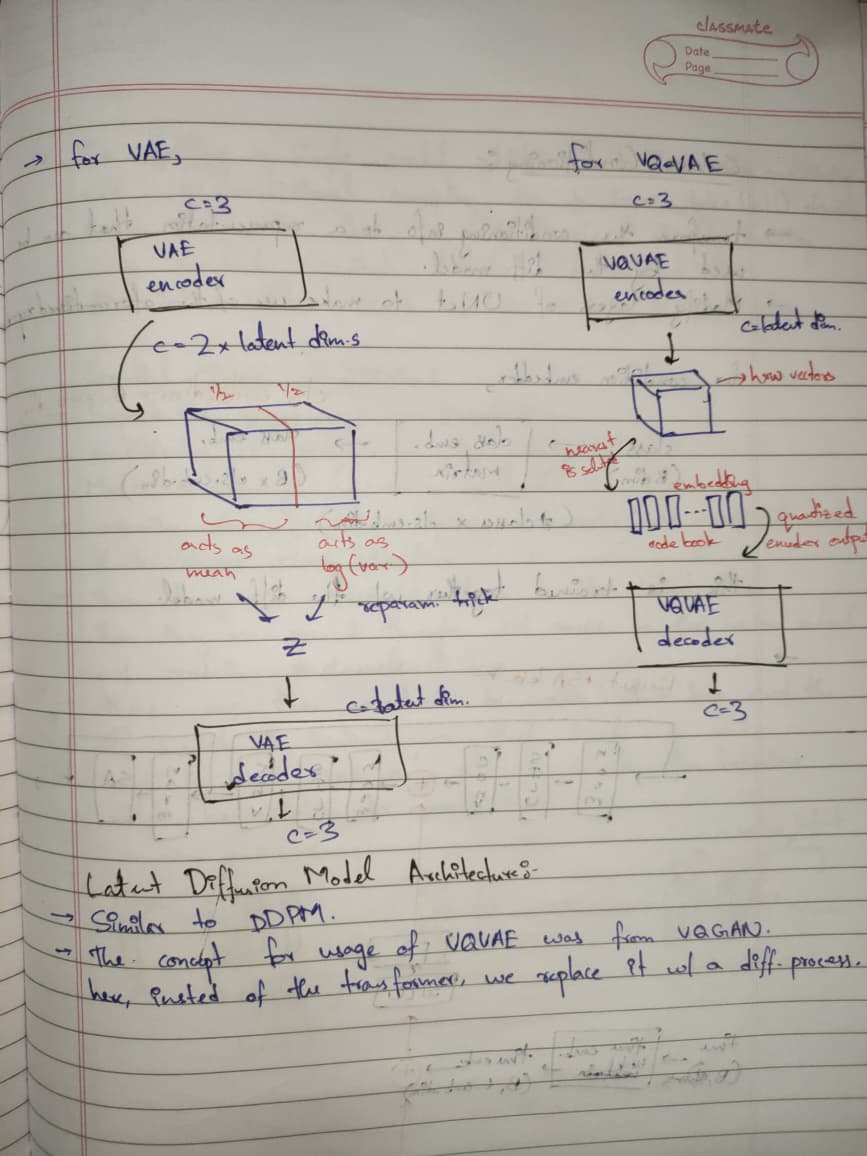
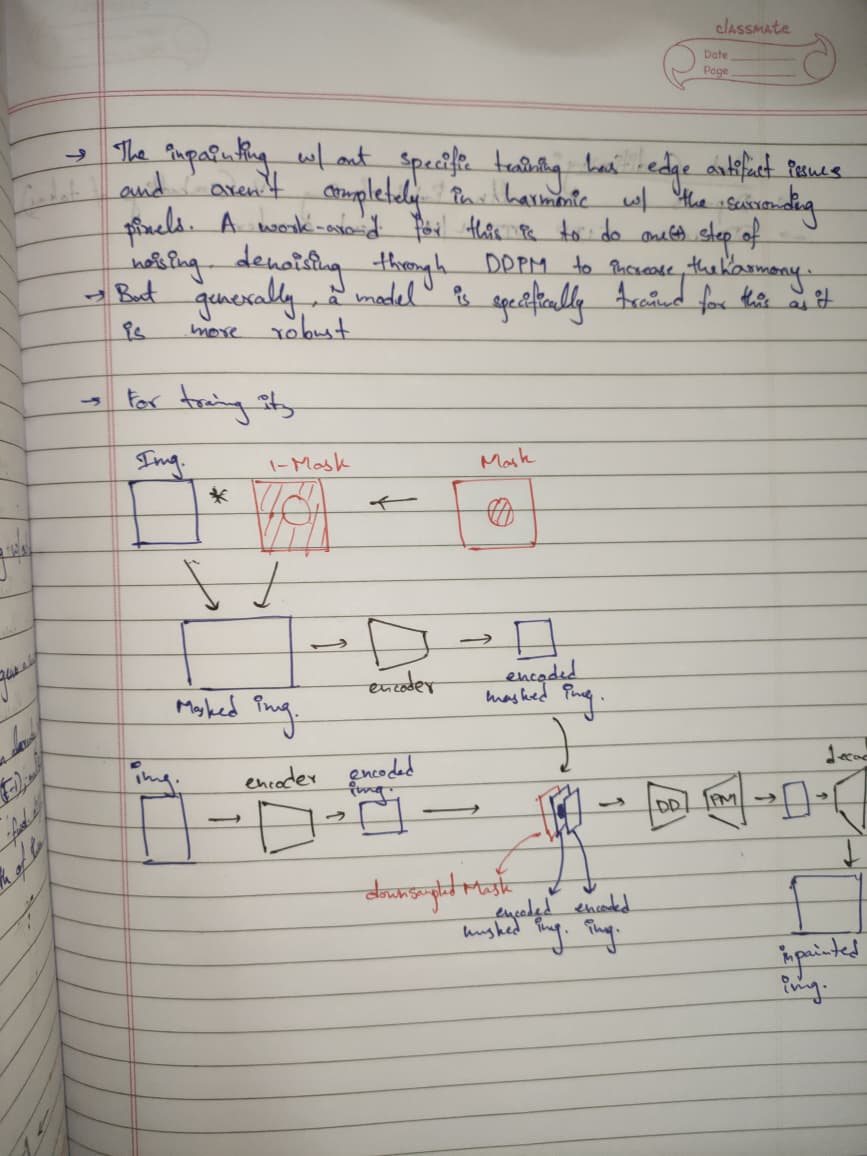
The notes covers the following:
- Latent Diffusion Models (LDMs)
- The Training Process
- Perceptual Loss
- Adversarial Loss
- Autoencoder Architecture
- LDM Architecture
- Class Conditioning
- Mask Conditioning (Semantic Synthesis)
- Super Resolution
- Inpainting
- Text Conditioning
Hand-written Notes