1. Abstract
AdaMuon augments Muon with two mutually dependent modules:
- a per-parameter second-moment (squared avg. of variance of gradients) modulation that captures orthogonal gradient updates to ensure update-level adaptivity
- each parameter adapts its learning rate depending on how gradients vary in its own direction.
- a RMS-aligned rescaling that regulates the overall update magnitude by aligning it with the intrinsic structure of the parameter space
- instead of blindly clipping or normalizing, AdaMuon rescales updates so their RMS matches the intrinsic structure of the parameter space).
2. Preliminary
2.1 Muon Optimizer
- Refer to my blog on Muon up on my Notion site
1. Momentum update
- Purpose: accumulate gradient information over time (like SGD with momentum). keeps a smoothed history of recent gradients.
- Interpretation: controls how fast history decays. means long memory; near means almost no momentum.
2. Compute orthogonal factor
- Goal: instead of using (or a scalar-rescaled version) directly as the update direction, Muon extracts the orthogonal/polar component of .
- Why orthogonal? The polar factor captures the direction/rotation part of (roughly the “direction” of the matrix, independent of singular values). This produces structured updates that respect parameter-space geometry (they are not purely per-coordinate scalings).
- How we compute it efficiently: full SVD of gives , and the orthogonal factor would be . Full SVD is expensive, so Muon approximates by computing and approximating with Newton–Schulz iterations.
3. Parameter update
- We apply the orthogonal factor as the update direction, scaled by scalar learning rate .
- This yields a structured step that preserves geometry (the orthogonal part gives a rotation-like or structure-preserving direction rather than per-coordinate scaling).
Variables:
- — weight matrix at iteration .
- — gradient of the loss w.r.t. at iteration .
- — momentum buffer at iteration (same shape as ).
- — number of Newton–Schulz iterations to approximate the polar factor (typical default ).
- — Frobenius norm.
- — identity matrix of size k×kk\times kk×k.
- — orthogonal/polar factor approximation for the momentum matrix (same shape as ).
- — function that returns the polar (orthogonal) factor of matrix using Newton–Schulz iterations (detailed below).
2.2 Scaling up for Muon
- Muon - for 2D parameters (linear layers, weight matrices)
- Adam/AdamW - for 1D parameters (biases, layerNorm weights)
- Muon is scalable for LLM training, Liu et al. proposed to align the update scale of Muon with that of Adam, thereby allowing both optimizers to share a unified learning rate.
- — weight decay ratio
- This allows the optimizer to control the update RMS and also inherit the learning rate schedule of Adam, while still benefiting from Muon’s structured and geometry-preserving updates.
3. Algorithm
3.1 From Structured Updates to Variance-Aware Scaling
- Newton’s method uses curvature (via the Hessian Matrix or its inverse) to get locally optimal update directions. Full Hessian is too large for modern deep models so one uses approximations like the Fisher Information Matrix (FIM).
- Optimizers like Adam or RMSProp estimate gradient variance via exponential moving averages of squared gradients. This gives adaptive step sizes depending on how noisy the gradients are.
- Since Muon uses polar decomposition via Newton-Schulz iterations to get , the identity
(explained in detail at The Polar Decomposition) captures second-order interactions across rows and columns, similarly to matrix-aware optimizers like Shampoo. But Muon doesn’t maintain full covariance or Hessian matrices. This is what gives Muon its row-/column-wise second-order sensitivity without computing full Hessian or full covariance matrices.
-
While the orthogonal update captures global / matrix-level structure, it does not capture element-level gradient variance:
- Some positions in the weight matrix may be extremely noisy (variance high), others very stable (variance low).
- Uniform update magnitude (same scale for all entries) may cause:
- Overshooting in high‐variance entries
- Very slow/ineffective updates in low-variance entries
-
Goal: keep the geometry-aware structure of Muon (via orthogonal updates), and add adaptivity at the element-level (fine-grained), like Adam does.
-
Approach:
- Use Muon’s orthogonal direction as the base structured direction.
- Compute an element-wise second moment (variance estimate) over the entries of .
- Use that variance estimate to modulate (scale) the entries of : downweight those with high variance (noisy), upweight or preserve those with low variance (stable).
-
This modulation happens after orthogonal decomposition which ensures variance tracking happens on a “cleaned-up” version of the update direction (which has the large directional / global effects removed).
-
Polar decomposition gives globally coherent, geometry-preserving update directions. Variance modulation gives adaptivity at coordinate level, better handling heterogeneity of gradient signals. Combined, they help avoid instabilities due to noise, allow faster learning in low-variance coordinates, while preserving structure.
3.2 Muon with Second-Moment Modulation
What is added on top of Muon
AdaMuon is an extension of the Muon optimizer, incorporating two extra mechanisms:
- A second-moment estimator (operating element-wise, on the diagonal).
- A norm-based global rescaling (to align the overall update magnitude, analogous to the RMS behavior in Adam).
- The core structured update of Muon (via polar decomposition/orthogonalization) is retained. AdaMuon does not replace this but augments it, making the update magnitude adaptive at the element level rather than uniform across all entries of the update matrix.
Equations & computation
1. Flatten the orthogonal update:
(Here, is flattened into a vector .)
2. Second moment (variance) tracking, element-wise:
where is the element-wise square, and is a decay parameter close to 1.
3. Bias correction:
This compensates for initialization bias since is typically initialized to zero.
4. Adaptive update direction: Define the adjusted vector via element-wise division:
where is a small constant for numerical stability.
5. Reshaping and global rescaling (RMS-aligned):
- Reshape back to matrix form: .
- Compute the RMS (root mean square) of : .
- Then, perform the final parameter update:
where:
- is the learning rate,
- is the weight decay coefficient,
- is an empirically chosen constant scalar coefficient to align with Adam’s update scale.
Purpose & intuition
- Second-moment modulation: Allows AdaMuon to downweight coordinates with high noise (high variance) and upweight or preserve those that are stable (low variance). This helps prevent overshooting and instability in noisy directions.
- Global (RMS) rescaling: Ensures the overall magnitude of the update remains in a reasonable range, aligned with Adam’s scale. This provides consistency and allows for the reuse of standard learning rate schedules.
- Variance tracking post-orthogonalization: Ensures the update direction has already been geometrically “smoothed” (global structure normalized). This prevents element-wise adaptivity from undoing the benefits of the structural normalization.
Pseudocode

3.3 RMS-Aligned Rescaling
Purpose
- Ensure AdaMuon’s update magnitudes are compatible with learning-rate schedules designed for Adam (or Adam-style optimizers).
- Without this, the updates’ size can drift (get too small or too large), which breaks assumptions built into tuning schedules.
Key concept: dimension-aware target scale
- AdaMuon rescales its adaptive update so that the update’s norm (magnitude) matches a consistent target that depends on the parameter matrix dimensions.
- This uses matrix norms (Frobenius norm) and knowledge of dimensions , of the weight matrix .
Equation & operations
Given:
- = the matrix after variance-aware scaling and reshaping (same shape as original update).
- = Frobenius norm of .
- = dimensions of weight matrix .
Then:
- Rescale to enforce a Frobenius-norm based target norm:
- (Here is a small constant for numerical stability.)
- Note: The paper sometimes writes (contextually interpreted as ).
- Full parameter update (including weight decay and learning rate):
- Sometimes expressed equivalently as:
Variables
- — rescaled orthogonal update matrix (after second-moment modulation).
- — Frobenius norm: .
- — dimensions of the weight matrix .
- — small positive scalar for numerical stability.
- — learning rate.
- — weight decay.
- — scaling factor (often or similar) used earlier to align with Adam’s scale.
4. Experiment
4.1 Experimental Setup
- Base Implementation
- Framework: nanoGPT (Karpathy, 2022)
- Architecture: GPT-2 (Radford et al., 2019)
- Dataset: OpenWebText (Gokaslan et al., 2019)
- Data Splits
- Training set: ~9B tokens
- Validation set: ~4.4M tokens
- Tokenization: Standard GPT-2 tokenizer
- Model Scales Evaluated
- GPT-2 Small: 125M parameters
- GPT-2 Medium: 355M parameters
- GPT-2 Large: 770M parameters
- GPT-2 XL: 1.5B parameters
- Default nanoGPT Configurations
- Bias terms: Removed from all linear layers
- Activation function: GeLU
- Dropout: 0.0 for all layers
- Modifications Made
- Replace learned positional embeddings (WPE) with Rotary Positional Embedding (RoPE) (Su et al., 2024)
- Replace cosine learning rate schedule with Warmup-Stable-Decay (WSD) policy
- Training Setup
- Training tokens: ~50B tokens
- Training steps: 100K steps
- Warmup: 2K steps
- Context length: 1024 tokens (for all models)
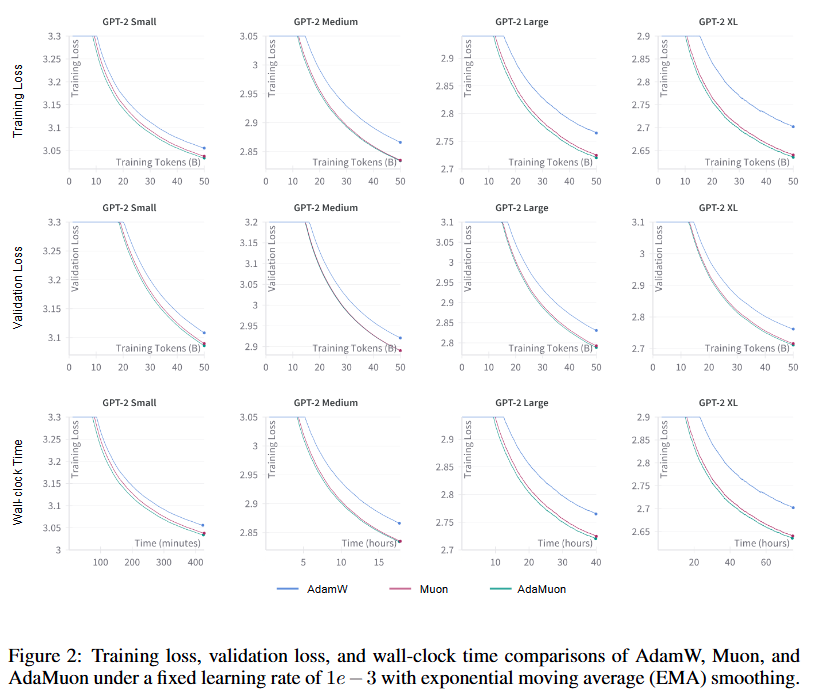
4.2 Result
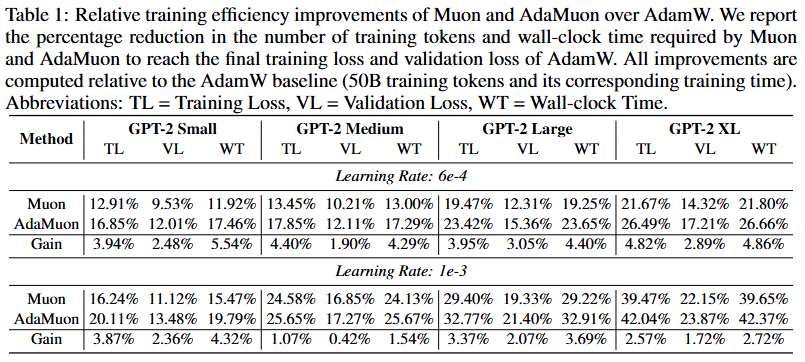
- Efficiency Gains over AdamW
- Both Muon and AdaMuon reduce the number of training tokens and wall-clock time needed to match AdamW’s final training and validation loss (at 50B tokens).
- AdaMuon Superiority
- AdaMuon consistently achieves the largest improvements across all model scales.
- Shows faster convergence compared to both AdamW and Muon.
- Convergence and Generalization
- Figure below show that AdaMuon outperforms both baselines (AdamW and Muon) in:
- Training loss reduction speed
- Validation loss reduction speed
- Generalization performance
- Figure below show that AdaMuon outperforms both baselines (AdamW and Muon) in:
- Wall-Clock Cost
- AdaMuon has a lower per-iteration wall-clock cost than Muon.
- Its cost remains comparable to AdamW, despite additional mechanisms.
- Overhead Analysis
- Incorporating second-moment modulation and RMS-aligned rescaling adds negligible computational overhead.
- These modifications lead to stabilized and more efficient optimization trajectories.
5. Conclusion
lr =
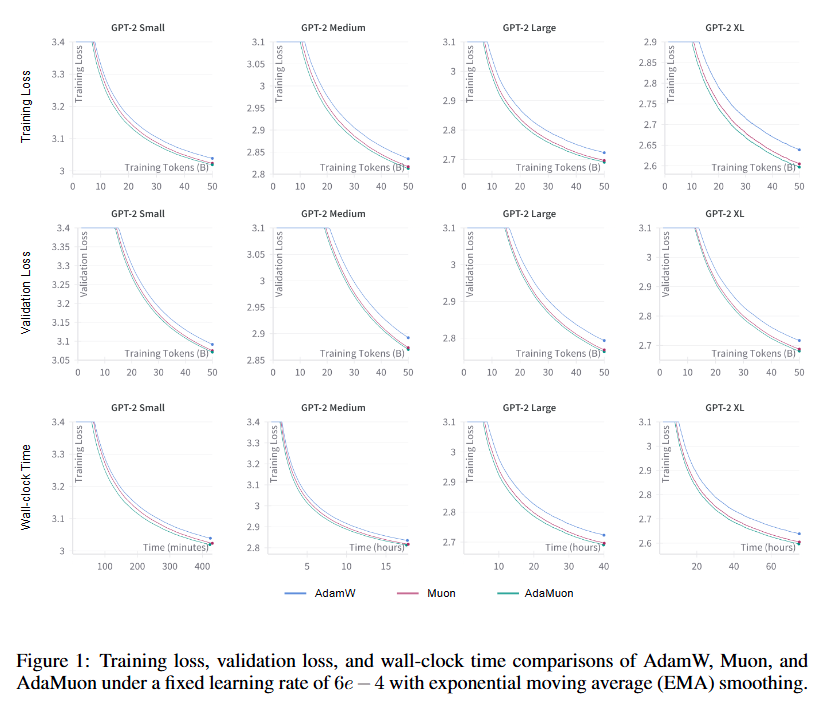
lr =