High-Resolution Image Synthesis with Latent Diffusion Models
Feb 04, 20251 min read
Introduction
Being likelihood-based models, they do not exhibit mode-collapse and training instabilities as GANs and, by heavily exploiting parameter sharing, they can model highly complex distributions of natural images without involving billions of parameters as in AR models.
To increase the accessibility of this powerful model class (DMs) and at the same time reduce its significant resource consumption, a method is needed that reduces the computational complexity for both training and sampling. Reducing the computational demands of DMs without impairing their performance is, therefore, key to enhance their accessibility.
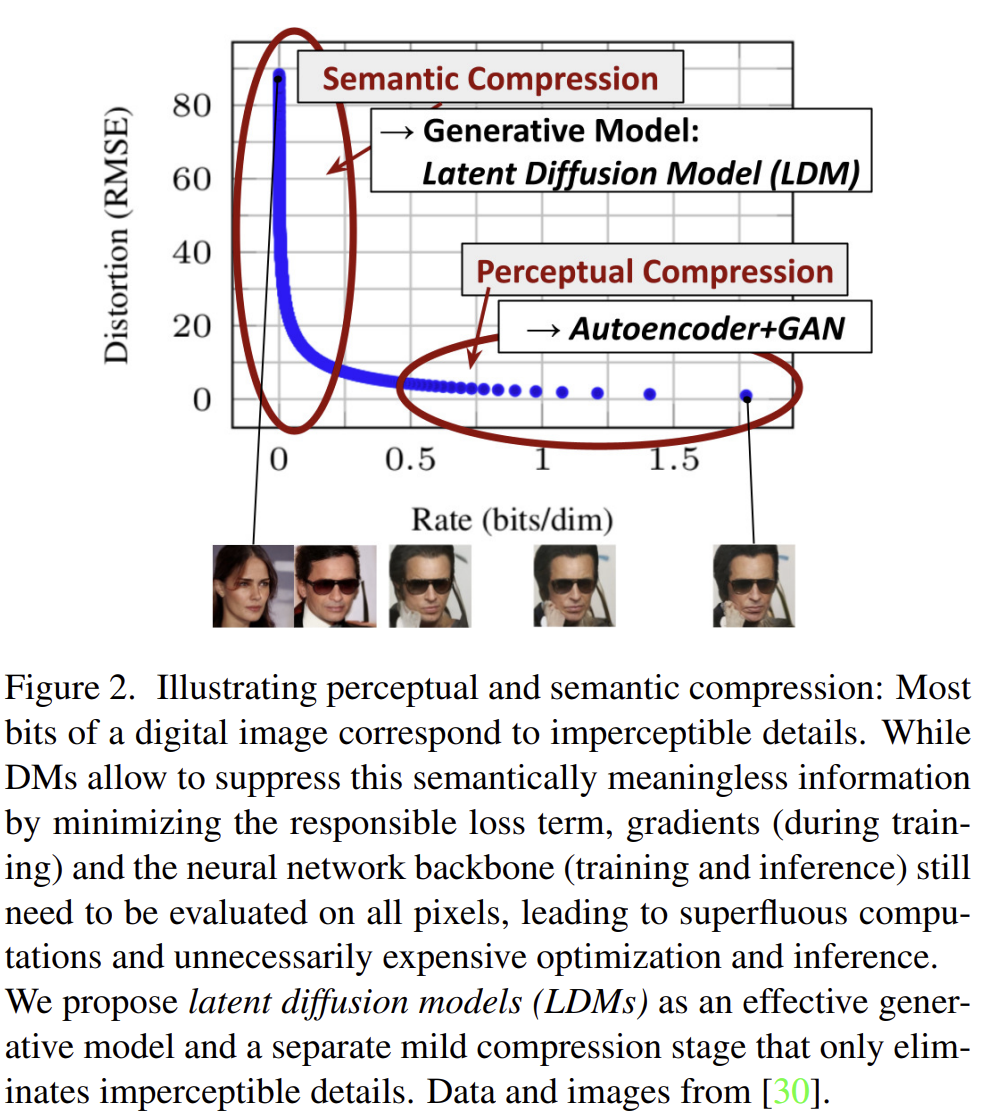
Departure to Latent Space Our approach starts with the analysis of already trained diffusion models in pixel space: Fig. 2 shows the rate-distortion trade-off of a trained model.
Learning can be roughly divided into two stages:
perceptual compression stage: Removes high-frequency details but still learns little semantic variation.
Semantic Compression: The actual generative model learns the semantic and conceptual composition of the data.
We thus aim to first find a perceptually equivalent, but computationally more suitable space, in which we will train diffusion models for high-resolution image synthesis.
Training is divided into two parts:
Autoencoder Training: Here, we train an AE which will provide